Weil ich jedes Mal das Würgen kriege, wenn Medienvertreter über die pösen pösen Ad-Blocker meckern und wie das Internet ohne Werbung keine Inhalte hätte. Weil es niemanden etwas angeht, wer, was, wann und wo liest. Weil ich https://pad.systemli.org/p/SSL-Zeitung eine tolle Initiative finde. Weil Gephi Spaß bringt. :)
 Lightbeam for Firefox ist ein nettes Tool, um Verbindungen zwischen Webseiten zu tracken und visualisieren. Ich habe es installiert und rund 90 Internetauftritte zufälliger Zeitungen und Magazine aufgerufen (Liste am Ende dieses Beitrags). Ich habe dabei “klassische” Medien bevorzugt
Lightbeam for Firefox ist ein nettes Tool, um Verbindungen zwischen Webseiten zu tracken und visualisieren. Ich habe es installiert und rund 90 Internetauftritte zufälliger Zeitungen und Magazine aufgerufen (Liste am Ende dieses Beitrags). Ich habe dabei “klassische” Medien bevorzugt
YOU HAVE VISITED 92 SITEs
YOU HAVE CONNECTED WITH 260 THIRD PARTY SITEs
Yumm yumm! Leider ist der eingebaute Graph ziemlich hässlich und unübersichtlich. Daher habe ich die Daten exportiert, etwas umformatiert und in Gephi visualisiert.
In Lightbeam: “Save Data”. Es kommt eine lightbeamData.json-Datei raus. Diese hab ich dann (per Holzhammer) mit GNU/Linux-Bordmitteln bekämpft. Erst mit sed Zeilenumbrüche eingefügt, dann mit awk die interessanten Felder extrahiert, mit sed bereinigt und dann Duplikate entfernt:
sed 's/\],/\],\n/g' lightbeamData.json | awk -F "," '{print $1"\t"$2}' | sed 's/[\["]//g' | sort | uniq > lightbeamData.tsv
Um sie anschließend direkt in Gephi laden zu können, müssen die Spalten Titel haben. Also zum Beispiel einfach “source[TAB]target” in die erste Zeile einfügen.
In Gephi ist es dann eigentlich ganz einfach. Neues Projekt, Data Laboratory -> Import Spreadsheet. Die lightbeamData.tsv-Datei auswählen. Tab als Trennzeichen und als Edges-Tabelle laden. Next -> Finish, Fertig!
Im Overview unten auf das Label Attributes Icon klicken und “Id” auswählen, jetzt werden die Nodes beschriftet. Links bei Ranking (Degree) -> Label Size als maximale Größe zum Beispiel 2 auswählen. Mit einem der Slider unten kann man die gesamte Textgröße dynamisch ändern. Und dann mit den Layouts herumspielen. Um ein schönes Endprodukt zu bekommen ist Label Adjust ganz furchtbar toll (verfälscht aber natürlich vorherige Layout-Algorithmen). Per Mouseover kann man sich benachbarte Nodes anzeigen lassen. Da kommt dann zum Beispiel sowas bei raus:
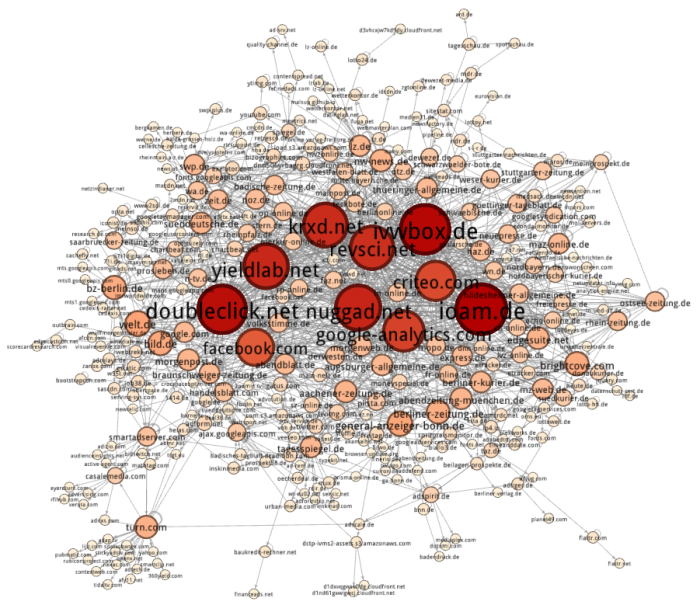

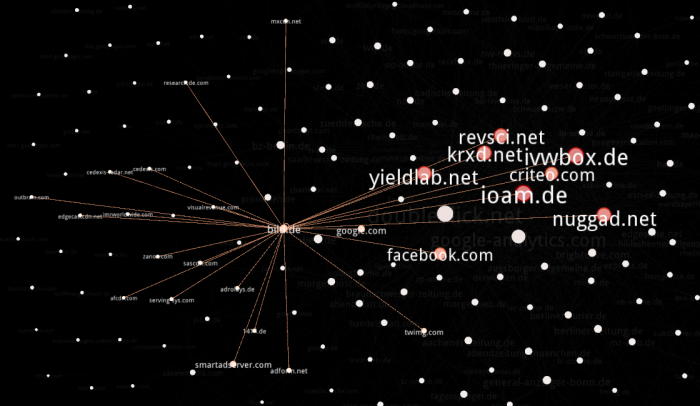

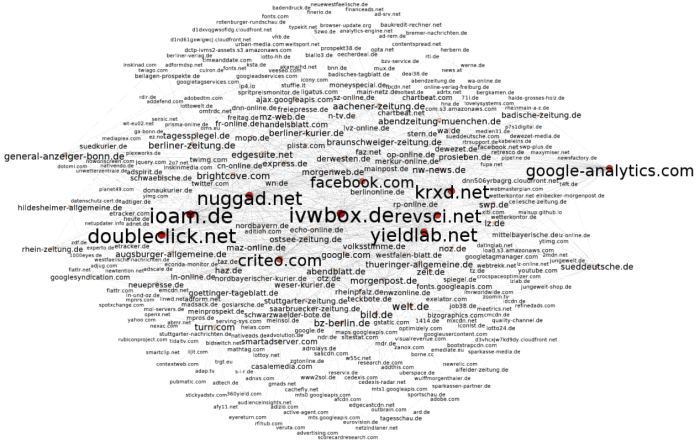
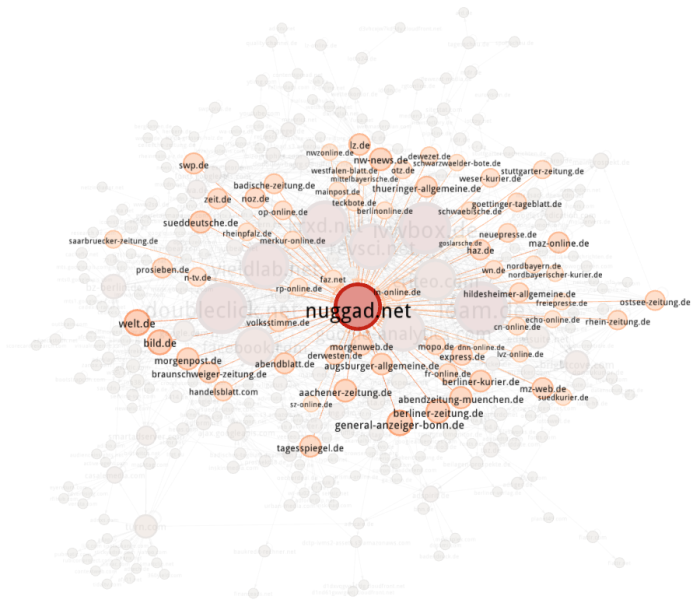


Fazit: HTTP Switchboard oder Request Policy lohnen sich.
Die folgenden Domains wurden besucht:
http://www.aachener-zeitung.de
http://www.abendblatt.de
http://www.abendzeitung-muenchen.de
http://www.alfelder-zeitung.de
http://www.augsburger-allgemeine.de
http://www.badische-zeitung.de
http://www.badisches-tagblatt.de
http://www.berliner-kurier.de
http://www.berliner-zeitung.de
http://www.berlinonline.de
http://www.bild.de
http://www.bnn.de
http://www.braunschweiger-zeitung.de
http://www.bremer-nachrichten.de
http://www.bz-berlin.de
http://www.cellesche-zeitung.de
http://www.cn-online.de
http://www.derwesten.de
http://www.dewezet.de
http://www.dnn-online.de
http://www.donaukurier.de
http://www.echo-online.de
http://www.einbecker-morgenpost.de
http://www.express.de
http://www.faz.net
http://www.fr-online.de
http://www.freiepresse.de
http://www.freitag.de
http://www.general-anzeiger-bonn.de
http://www.goettinger-tageblatt.de
http://www.goslarsche.de
http://www.handelsblatt.com
http://www.haz.de
http://www.heute.de
http://www.hildesheimer-allgemeine.de
http://www.jungewelt.de
http://www.ln-online.de
http://www.lvz-online.de
http://www.lz-online.de
http://www.main-netz.de
http://www.mainpost.de
http://www.maz-online.de
http://www.mdr.de
http://www.merkur-online.de
http://www.mittelbayerische.de
http://www.mopo.de
http://www.morgenpost.de
http://www.morgenweb.de
http://www.mz-web.de
http://www.n-tv.de
http://www.ndr.de
http://www.neuepresse.de
http://www.neuewestfaelische.de
http://www.nordbayerischer-kurier.de
http://www.nordbayern.de
http://www.noz.de
http://www.nw-news.de
http://www.nwzonline.de
http://www.op-online.de
http://www.ostsee-zeitung.de
http://www.otz.de
http://www.prosieben.de
http://www.rhein-zeitung.de
http://www.rheinpfalz.de
http://www.rotenburger-rundschau.de
http://www.rp-online.de
http://www.saarbruecker-zeitung.de
http://www.schwaebische.de
http://www.schwarzwaelder-bote.de
http://www.spiegel.de
http://www.stern.de
http://www.stuttgarter-zeitung.de
http://www.sueddeutsche.de
http://www.suedkurier.de
http://www.swp.de
http://www.sz-online.de
http://www.tagesschau.de
http://www.tagesspiegel.de
http://www.taz.de
http://www.teckbote.de
http://www.thueringer-allgemeine.de
http://www.tz.de
http://www.volksstimme.de
http://www.wa.de
http://www.welt.de
http://www.weser-kurier.de
http://www.westfalen-blatt.de
http://www.wn.de
http://www.zeit.de
Heimlich versteckte Randnotizen:
Ja, ich habe die “guten” Seiten ignoriert, die sich ausserhalb der Spaghettibälle befinden. In Lightbeam waren dies: rotenburger-rundschau.de, einbecker-morgenpost.de, bremer-nachrichten.de, alfelder-zeitung.de, jungewelt.de, neuewestfaelische.de.
Da ich einige Domains direkt im Router blocke könnte die Wirklichkeit noch schlimmer aussehen.
Ich habe das Gefühl, dass Lightbeam mehr Verbindungen suggeriert/erzeugt, als tatsächlich anfallen…