Die HomepageJeder Eintrag im Transparenzportal Hamburg wurde gespieltMan konnte Suchen speichern und bei neuen Ergebnissen eine Mail erhalten
Ein Beispiel für einen EintragEin Eintrag mit mehreren verknüpften Resourcen
Die Idee war ursprünglich, dass dort Kommentare und Diskussionen zu den im Transparenzportal Hamburg (TPHH) veröffentlichten Datensätzen gepostet werden könnten. Und das vielleicht sogar direkt im TPHH eingebettet.
Dazu hat ein Python-Skript (als Bot namens “Heidi Kabel” ;) ) jede Minute die API des TPHH nach neuen Datensätzen gefragt, die Metadaten abgerufen und sie schön formatiert und aufbereitet als Foren-Threads gepostet. Ein spaßiges Bastel-Projekt, irgendwann 2019.
Die Dokumentation für die Forumsinstallation und der Code für den Bot liegen in:
Naja, dann kam Corona und Treffen von Code for Hamburg gab’s eh schon kaum noch. Die Seite hat praktisch niemand außer mir genutzt, es gab keine 10 Posts, die nicht vom Bot waren. Mit der Einbindung im TPHH wurde es auch nichts (ich hatte mich aber auch nicht drum gekümmert).
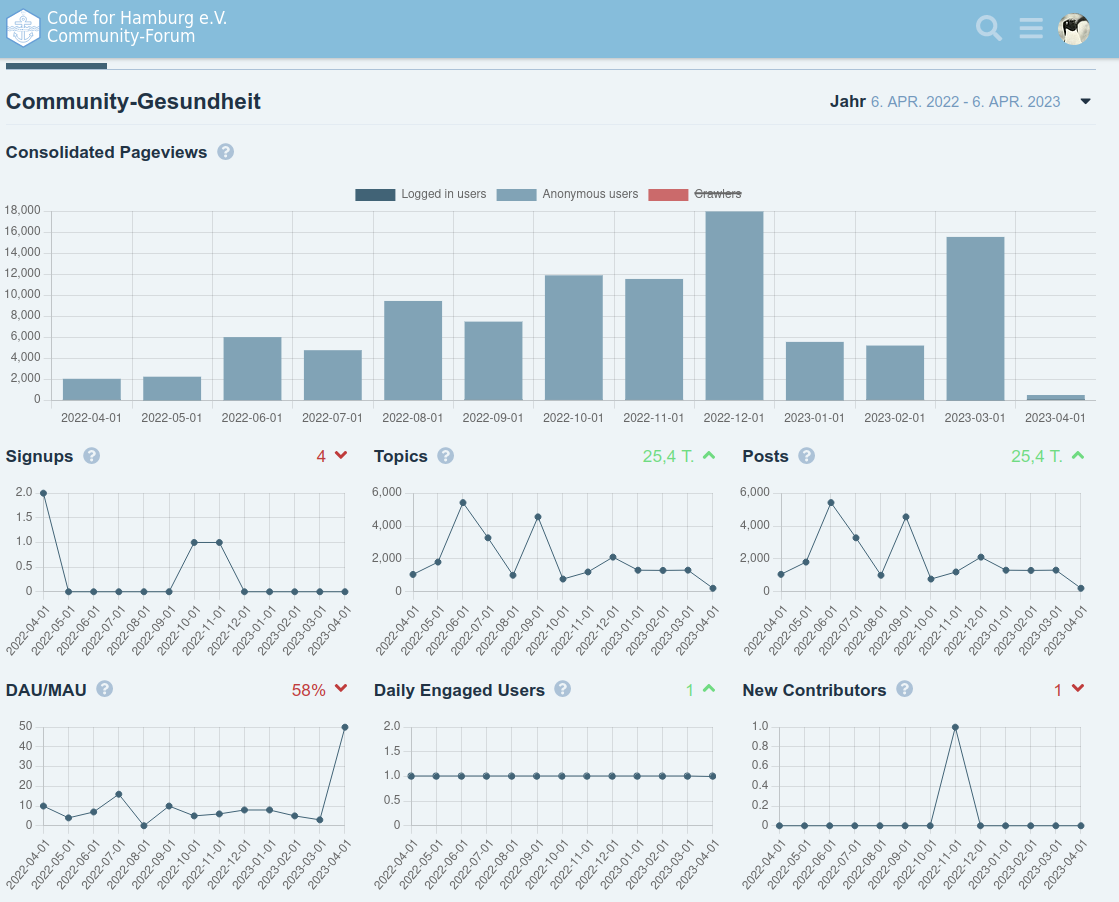
“Angesagte” Posts mit vielen Views
Pageviews exklusive (erkannte) CrawlerTop Referred Topics (keine Ahnung wo sie verlinkt wurden)
Der tägliche User war unser TPHH-Spiegel-Bot, die Posts/Topics auch
Ich hatte es für mich selbst noch als einfaches Interface für die Daten und als praktischen Benachrichtigungsservice auf bestimmte Keywords genutzt, aber jetzt klappt das Update der Forensoftware nicht mehr (Bug von Discourse mit angeblich nicht mehr einzigartigen Tags und es gab keine Rückmeldung auf meine Fragen, von daher …) und ich will da nix auf veralteter Software laufen lassen. Übernehmen wollte es niemand aus dem Verein und im Fediverse hat sich auch niemand gemeldet. Von daher mach ich die Tage das Licht aus.
PS: Ich hoffe Code for Hamburg wird irgendwann mal wieder reaktiviert, mit regelmäßigen Treffen, wo gehackt und gebastelt wird. Toi toi toi!
Not sure why I never posted this last year but I did the #30DayMapChallenge in a single day, streamed live via a self-hosted Owncast instance. It was … insane and fun. This year I will do it again, on the 26th of November.
Here are most of the maps I made last year:
Some notes I kept, please bug me about recovering the others from my Twitter archive (I deleted old tweets a bit too early):
18 Water (DGM-W 2010 Unter- und Außenelbe, Wasserstraßen- und Schifffahrtsverwaltung des Bundes, http://kuestendaten.de, 2010)
20 Movement: Emojitions on a curvy trajectory. State changes depending on the curvyness ahead. Background: (C) OpenStreetMap Contributors <3
21 Elevation with qgis2threejs (It’s art, I swear!
22 Boundaries: Inspired by Command and Conquer Red Alert. Background by Spiney (CC-BY 3.0 / CC-BY-SA 3.0, https://opengameart.org/node/12098)
24 Historical: Buildings in Hamburg that were built before the war (at least to some not so great dataset). Data Lizenz: Datenlizenz Deutschland Namensnennung 2.0 (Freie und Hansestadt Hamburg, Landesbetrieb Geoinformation und Vermessung (LGV))
27 Heatmap: Outdoor advertisements (or something like that) in Hamburg. Fuck everything about that! Data Lizenz: Datenlizenz Deutschland Namensnennung 2.0 (Freie und Hansestadt Hamburg, Behörde für Verkehr und Mobilitätswende, (BVM))
28 Earth not flat. Using my colleague’s Beeline plugin to create lines between the airports I have flown too and the Globe Builder plugin by @gispofinland to make a globe.
https://suche.transparenz.hamburg.de.EXAMPLE.COM/api/action/resource_search?query=url: (“.EXAMPLE.COM” entfernen) liefert aktuell rund 200 Megabyte an JSON, da sollten alle Resourcen drin stecken oder zumindest die, die tatsächlich einen Datensatz referenzieren
Um es in normalen Editoren besser handlebar zu machen, hilft json_pp:
As I will shut it down (no reason, just decluttering) here’s how it works so you can run your own:
Have aerial images with a permissive license
Register a Twitter account and set it up for posting via API access
Write code to pick an image and post it
Done!
Okok, I am kidding.
I used https://suche.transparenz.hamburg.de/dataset/digitale-orthophotos-belaubt-hamburg3 as data source because they have a CC-BY like license, allowing such a project without any legal complications. As a side benefit these images are already provided in tiles: There is not one big image of the whole region but 1km² image tiles. Perfect for random selection, quick resizing and posting.
Registering a Twitter account and setting it up is a privacy nightmare and, being a good human being as you are, you ought hate any part of it. I followed the Twython tutorial for OAuth1 in a live Python interpreter session which was fairly painless. If you do not want to link a phone number to your Twitter account (see above for how you should feel about that), this approach worked for me in the past but I bet they use regional profiling or worse so your luck might differ.
Next you need some code to do the work for you automatically. Here is what I wrote with Pillow==7.0.0 for the image processing and twython==3.8.2 for posting:
import glob
import random
from io import BytesIO
from PIL import Image
from twython import Twython
## Initialise Twitter
# use a Python interpreter to follow the stops on
# https://twython.readthedocs.io/en/latest/usage/starting_out.html#oauth-1-user-authentication
# don't rush, there are some intermediate keys iirc...
APP_KEY = '1234567890ABCDEFGHIJKLMNO'
APP_SECRET = '12345678901234567890123456F8U0CAKATAWAIATATAEARAAA'
OAUTH_TOKEN = '1234567890123456789123456F8U0CAKATAWAIATATAEARAAAA'
OAUTH_TOKEN_SECRET = '123456789012345678901234567890FFSFFSFFSFFSFFS'
twitter = Twython(APP_KEY, APP_SECRET, OAUTH_TOKEN, OAUTH_TOKEN_SECRET)
## Prepare the image
# via https://twython.readthedocs.io/en/latest/usage/advanced_usage.html#posting-a-status-with-an-editing-image
# Pick the image
jpegs = glob.glob("DOP20_HH_sommerbefliegung_2019.zip/*.jpg")
todays_image = random.choice(jpegs)
print(f"Today we will post {todays_image}")
photo = Image.open(todays_image)
# Resize the image
basewidth = 1000
wpercent = (basewidth / float(photo.size[0]))
height = int((float(photo.size[1]) * float(wpercent)))
resized_photo = photo.resize((basewidth, height), Image.ANTIALIAS)
# "Save" the resulting image in temporary memory
stream = BytesIO()
resized_photo.save(stream, format='JPEG')
stream.seek(0)
## We've got what we need, let's tweet
license = "dl-de/by-2-0 (Freie und Hansestadt Hamburg, Landesbetrieb Geoinformation und Vermessung)"
tweet = f"Das ist #IrgendwoInHH, aber wo denn nur?\n\n#codeforhamburg\n\nBild: {license}"
response = twitter.upload_media(media=stream)
twitter.update_status(status=tweet, media_ids=[response['media_id']])
First we initialize that Twython thingie, then we pick a random image from a directory of .jpg files, then we resize it to a maximum of 1000 pixels (you can simplify that if your images are square…) and finally we post it to Twitter.
Set up a cronjob or systemd timer or alarm clock to run the script as often as you like and that’s it.
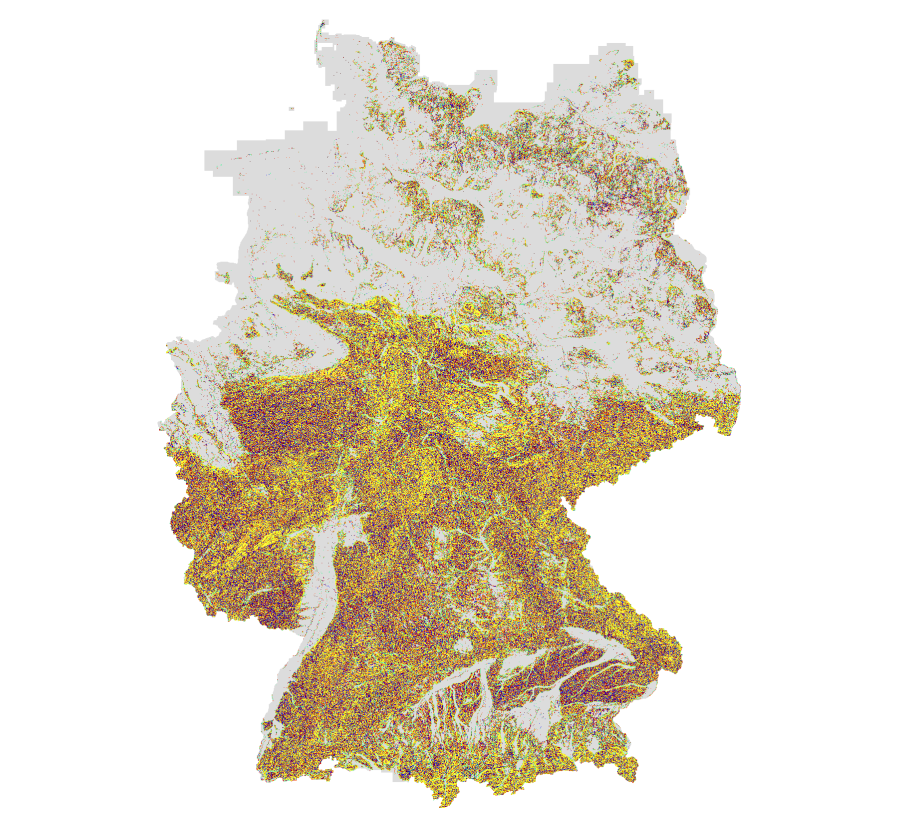
Egal. Das ist ja großartig! Da werden eine Menge von Anwendungen ermöglicht (Sichtachsen! Verschattungen! Vermaschung! VR! AR!) und verschiedenste Akteure werden die Daten absolut feiern. Auch wenn es mit 1 Meter Auflösung wirklich mies grob ist, auf ein 1 Meter Gitter gerastert ist (nicht ausgedünnt, d. h. es ist teilweise stärker verfälscht und “daneben”) und “nur” bildbasiert (nicht gescannt) ist, geht da schon einiges mit.
Ausprobieren! Im Browser!
Achtung, frickelige Bedienung! Am besten den WASD-Möwen-Modus nutzen, mit Speed 1000. Oder mit einem Doppelklick irgendwo hinzoomen.
Für 2018 liegen die Daten als 12768 einzelne XYZ-Kacheln vor, also als super ineffiziente Textdateien. Insgesamt sind es rund 22 Gigabyte. Für 2020 sind es stattdessen 827 größere Kacheln, aber ebenfalls in XYZ mit einem ähnlichem Platzbedarf.
Schönerweise gibt es freie Tools wie LAStools‘ txt2las, was sie schnell und einfach ins super effiziente LAZ-Format umwandeln kann:
und 4 Minuten später ist die interaktive 3D-Webanwendung fertig, wegen der zusätzlichen Octree-Struktur jetzt bei rund 3 Gigabyte.
Punktwolke mit Farben aus Orthophoto einfärben
Die bereitgestellten Oberflächenmodelle sind so schlicht wie es nur geht, es sind reine XYZ-Daten ohne weitere Dimensionen wie Farbe o. ä.
Glücklicherweise gibt es ja auch die Orthophotos, eventuell wurde sogar dasselbe Bildmaterial genutzt? Da müsste mal jemand durch den Datenwust wühlen, die bei den DOPs werden die relevanten Metadaten nicht mitgeliefert…
Theoretisch könnte man sie also einfärben. Leider ist lascolor proprietär und kommt mit gruseligen, bösartigen Optionen, wenn man es wagt es “unlizenziert” zu nutzen (“Please note that the unlicensed version will (…) slightly change the LAS point order, and randomly add a tiny bit of white noise to the points coordinates once you exceed a certain number of points in the input file.”) und kann JPEG in GeoTIFF nicht lesen (so hab ich mir die DOPs aufbereitet). Eine Alternative ist das geniale PDAL. Mit einer Pipeline wie
ist die Punktwolke innerhalb von Minuten coloriert und kann dann wie gehabt mit PotreeConverter in einen interaktiven 3D-Viewer gesteckt werden.
Update 2023: "minor_version": "2" -> "minor_version": "4", damit LAS 1.4 rauskommt, um dann einfach COPC draus bauen zu können (Farben als 16-Bit, nicht 8-Bit). Und entsprechend noch ein Filter, um die Farben auf den 16-Bit-Wertebereich zu skalieren, das passiert leider nicht automatisch.
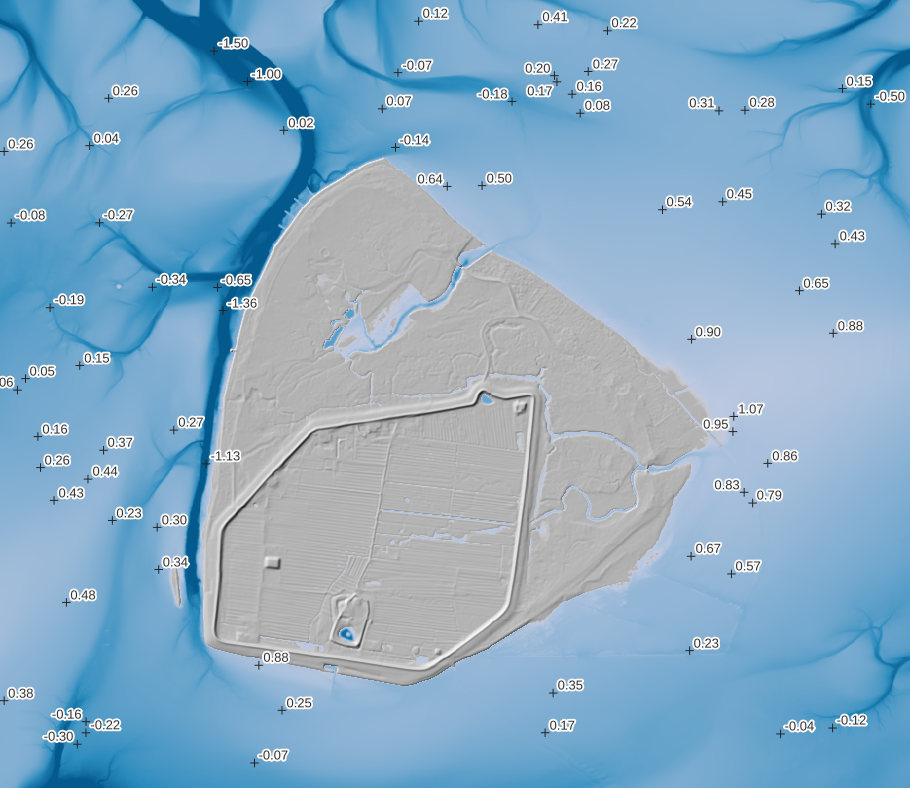
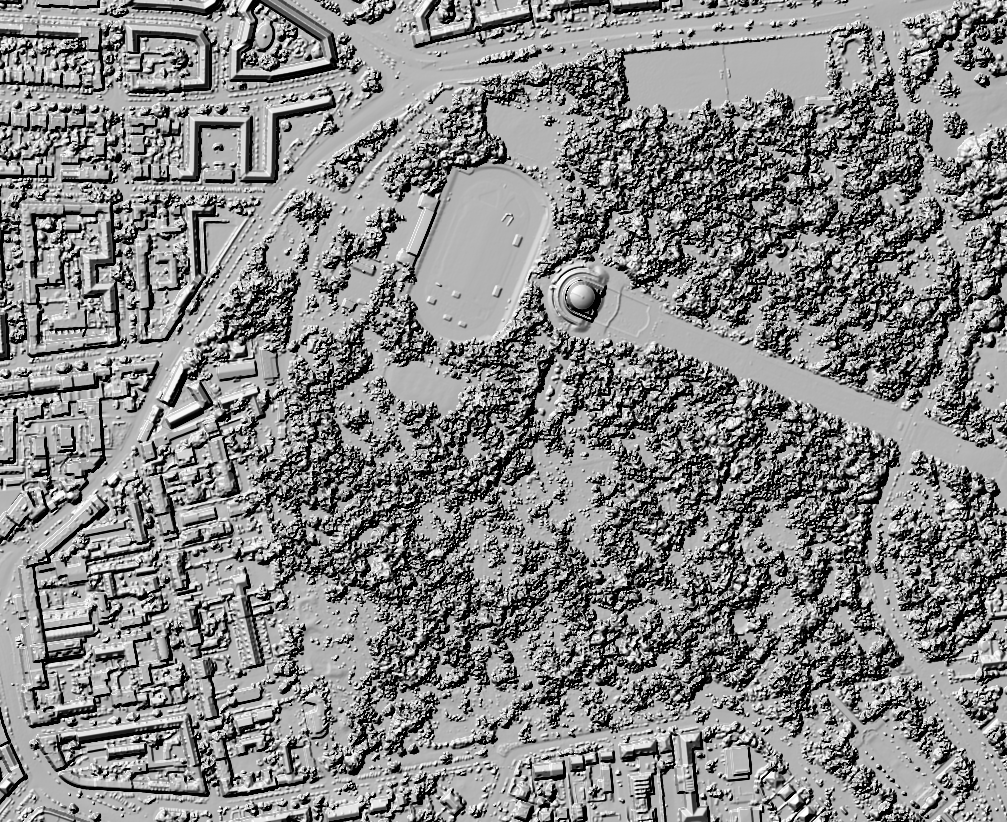
Das Ergebnis ist besser als erwartet, da es scheinbar tatsächlich die selben Bilddaten sind (für beide Jahre). Andererseits ist es auch nicht wirklich schick, da die DOPs nicht als True Orthophoto vorliegen und damit höhere Gebäude gekippt in den Bilder abgebildet sind. Sieht man hier schön am Planetarium.
Cloud-Optimized Point Cloud
Als Cloud-Optimized Point Cloud umwandeln kann man das Resultat einfach mit untwine (mit pdal pipeline braucht man immens viel RAM (>64GB), da die Umwandlung nach COPC hier nicht den Streaming Mode nutzen kann):
Anschließend auf einem Server (mit entsprechenden Access-Control-Allow-Headern) gelagert, kann die Punktwolke super einfach mit https://viewer.copc.io/?resources=https://example.com/pointcloud.copc.laz im Browser verwendet werden. Ganz ohne Umwandlung in viele Unterdateien wie beim PotreeConverter.
DOM als GeoTIFF
Wer es lieber als GeoTIFF haben möchte, hat es etwas schwerer, denn GDAL kommt mit dieser Art von Kacheln (mit Lücken und in der bereitgestellten Sortierung) nicht gut klar. Mein Goto-Tool dafür ist GMT.
Hier mal im Vergleich mit dem DGM1 als Schummerungen:
Vermaschung als 3D-Modell
Leider habe ich keine gute Lösung für die 3D-Vermaschung gefunden. tin-terrain und dem2mesh kommen nicht mit so großen Datenmengen auf einmal klar und weiter hab ich nicht geschaut. Wer da was gutes weiß kann sich bei mir bei nächster Gelegenheit Kekse oder Bier abholen. ;)
Daten hinter den Bildern und den Viewern Datenlizenz Deutschland Namensnennung 2.0, Freie und Hansestadt Hamburg, Landesbetrieb Geoinformation und Vermessung (LGV)
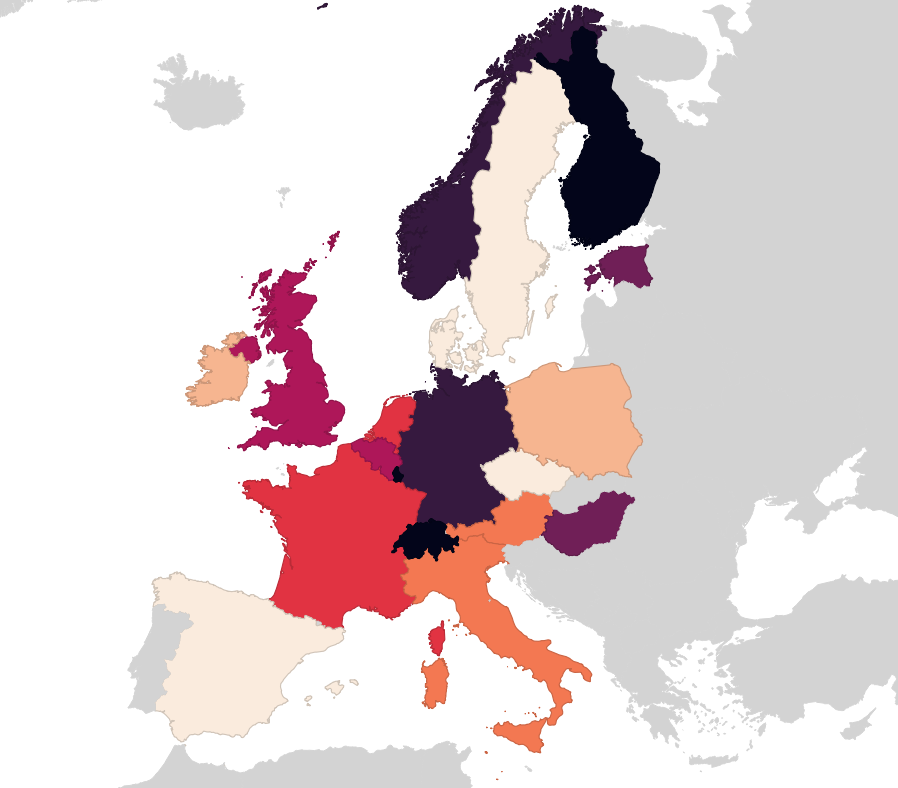
Je weniger transparent eine Fläche dargestellt ist, desto mehr Dokumente sind mit ihr verknüpft (ja, es ist ein Feature je Dokument D;). Eigentlich war die Seite anders aufgebaut, mit einem PDF-Viewer auf der rechten Seite. Aber da daten.transparenz.hamburg.de kein HTTPS kann (seid ihr auch so gespannt auf die UMTS-Auktion nächste Woche?), geht das aus Sicherheitsgründen nicht ohne ein Spiegeln der Daten oder einen Proxy.
Die Daten kommen größtenteils aus dem Transparenzportal. Für das Matching der angebenen Flurstücks-“IDs” zu den tatsächlichen Flurstücken war aber ein erheblicher Aufwand nötig. Das Drama ging bis hin zum Parsen aus PDFs, die mal so, mal so formatiert waren und natürlich auch voller Eingabefehler auf Behördenseite. Vielleicht schreibe ich da noch beizeiten mal einen Rant. TL;DR: Ohne die zugehörige Gemarkung ist mit einer Flurstücks-“ID” wie in den Daten angegeben keine räumliche Zuordnung möglich. In den veröffentlichten Daten stecken nur die Nenner der Flurstücksnummern, nicht aber die Gemarkungsnummern. Ziemlich absurd.
Das ganze ist nur ein Prototyp, vermutlich voller Fehler und fehlender Daten. Aber interessant und spaßig ist es, viel Freude also!
Es wäre noch eine MENGE zu tun, um das ganze rund zu machen. Falls du Lust hast, melde dich gerne. Es geht vom wilden Parsen, über Sonderregeln für kaputte Dokumente, zu Kartenstyling bis zur UI. Schön wäre es auch alles in einer anständigen Datenbank zu halten und nicht nur nach der räumlichen Dimension durchsuchen zu können.
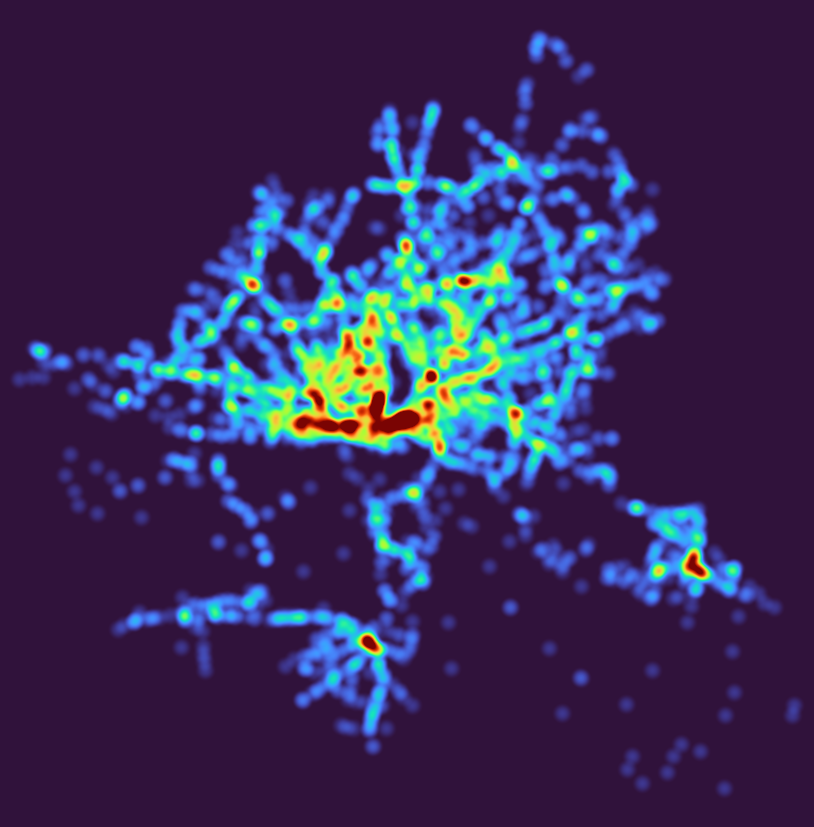
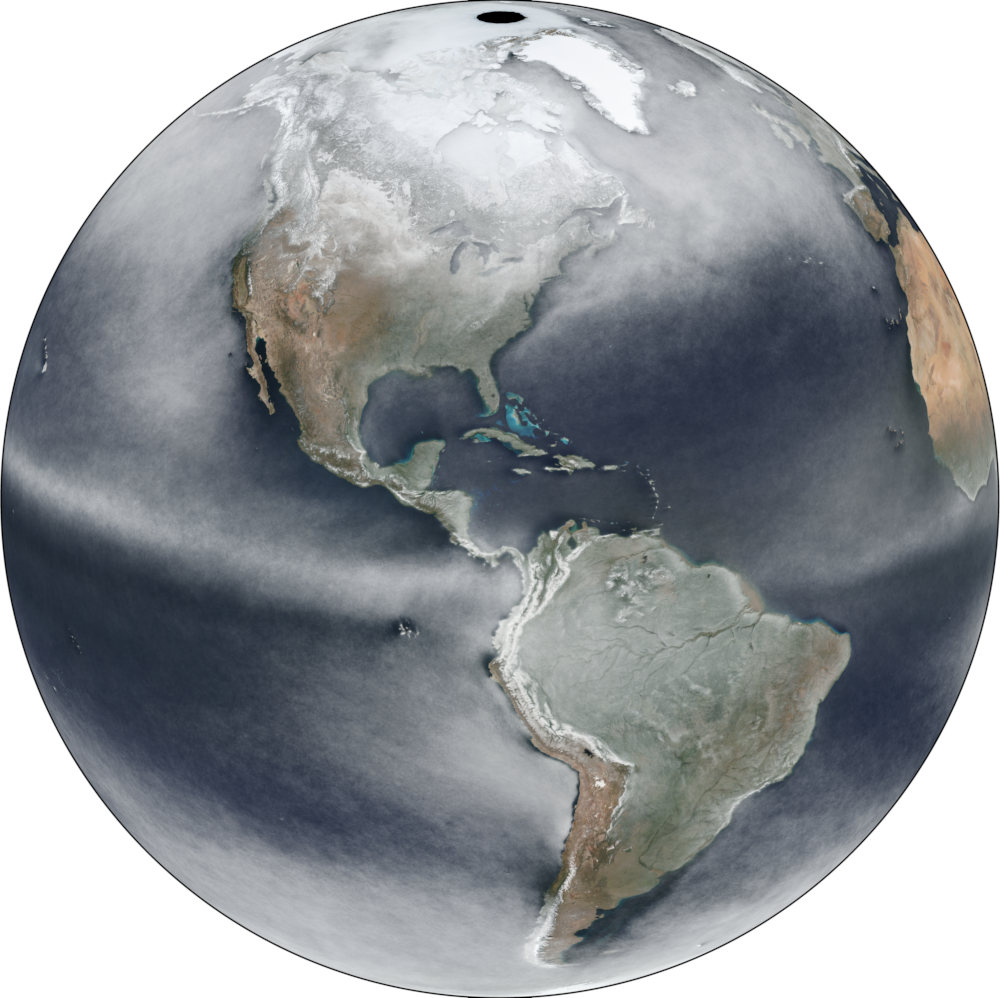
You can see fascinating patterns, e.g. “downstream” of islands in the ocean or following big rivers like the Amazon. Be wary though as snow and clouds look the same here.
Bit of EuropeIslands in the Atlantic OceanNorth AmericaParts of South-East AsiaSomewhere in RussiaAround IndiaAmazonCaribbeanAround Madagascar
It’s also fun to look at the maximum to see cloudless regions (this image is highly exaggerated and does not make too much sense anyways):
Many thanks to Joshua Stevens for motivation and infos on data availability! The initial idea was of course inspired by Charlie ‘vruba’ Lyod‘s Cloudless atlas works. I explored imagery on https://worldview.earthdata.nasa.gov/, grabbed Soumi VIIRS images via https://wiki.earthdata.nasa.gov/display/GIBS/GIBS+API+for+Developers and processed it in GDAL. Poke me repeatedly to blog about the process please. (2022: Or don’t, I didn’t document it back then and can’t remember the final specifics. I think I did use imagemagick’s -evaluate-sequence median but might have done something in vips2 instead. The 2020 approach via GDAL is much easier.)
Full resolution, georeferenced imagery as Cloud-Optimized GeoTIFF:
translates “so center of mass is at (0,0,0)” and scales to something smaller and rotates so that z is up. trimesh2’s documentation on the rot parameter is insufficient, I think my solution means “rotate by 90 degrees -1 times around x, 0 times around y, 0 times around z” or something like that. Look into the source if that helps you.
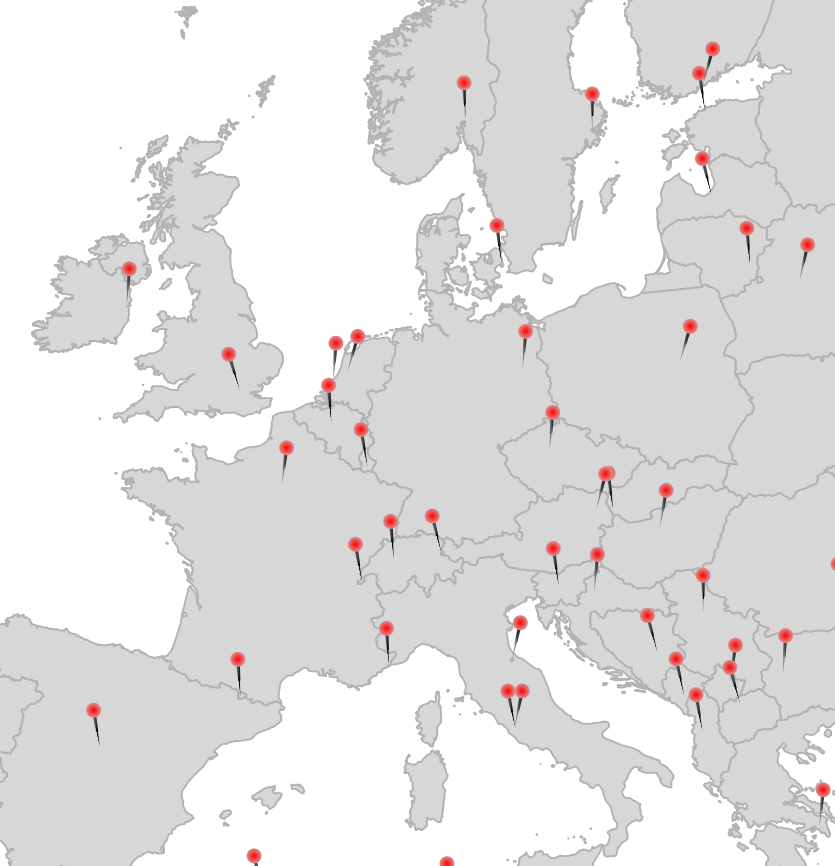
So we have something called “Lidl” which I know is a supermarket. And we have something else, with a potential name ending in “nden”. And that’s it.
If you have a global OSM database, this would be a simple query away. If you don’t have a global OSM database, the Overpass API let’s you query one. And overpass turbo can make it fun (not in this case though, I had a lot of trial and error until I found these nice examples in the Wiki).
I ended up looking for things within 50 meters to a Lidl named “-nden”

























































{kind=link}