+repage makes IM not write the offset to the files but actually crop “properly”. Maybe pdfcrop has such parameter too?
Installing a printer in Cups via a USB->Serial adapter
Make sure to “modprobe usbserial“. dmesg should show a printer being connected if you plug it in now. Then Cups should see it too.
RTTY with SDR# and fldigi (for the german DWD stations)
In SDR#: Use USB, filter bandwidth 1000. center the RTTY in your window.
In fldigi: Op Mode -> RTTY -> Custom. Set the carrier shift to custom and then enter 450 in the custom shift field below. Baud rate: 50, 5 bits per character, no parity, 1.5 stop bits. Save and Close. Make sure the Rv button is green!
CW decoding with SDR# and fldigi
In SDR#: Use the CW-L or CW-U preset. Tune so the morse code is right in the middle of your “reception window”.
In fldigi: Op Mode -> CW. Turn off squelch by making the SQL button not green but grey.
It works very well for non-human morse for me. Radio amateur morse is harder and so far full of “spelling errors”. :)
PDF to image with imagemagick/graphicsmagick
If you want to create images from PDF files, use for example mogrify -verbose -geometry 1600 -density 300 -format png *.pdf Without a decent “-density” parameter, you will probably get a blurry image as result.
echo 0 | tee /sys/devices/system/cpu/cpufreq/boost
Might work, might not, depending on unknown factors. Whatever, I just wanted to make some all-core-but-unimportant process to run without going 95°C. For that it worked perfectly well. CPU temps of a Ryzen 5 3600 after many hours of full utilization were at ~65°C. CPU frequencies were capped to 3.6GHz with this while jumping up to 4.2GHz (and ~94°C) without.
Obviously this has an impact on performance.
To re-enable just echo a 1 instead. This is reset anyways when you reboot your system.
if it is a one band raster you want to convert. For others you will have to adjust the readers.gdal.header part, e.g. to --readers.gdal.header="Red, Green, Blue". See https://pdal.io/stages/readers.gdal.html.
A follow-up to Average Earth from Space 2018 with a how-to. For each day of 2020 I took one global true color image of the whole planet and merged them together by using the most typical color per pixel. You can see cloud patterns in astonishing detail, global wind, permafrost (careful, white can be ice and/or clouds here) and more. Scroll to the bottom for interactive full resolution viewers.
Basically we will want to overlay one satellite image per day into one image for the whole year. You need two things: The images and the GDAL suite of geospatial processing tools.
set -e
set -u
# run like: $ bash gibs_viirs.sh 2020-10-05
# you get: VIIRS_SNPP_CorrectedReflectance_TrueColor-2020-10-05.tif
# in ~15 minutes and at ~600 megabytes for 32768x16384 pixels
# based on https://gist.github.com/jscarto/6c0413f4820ed5141744e96e19f31205
# https://gibs.earthdata.nasa.gov/wmts/epsg4326/best/1.0.0/WMTSCapabilities.xml
# VIIRS_SNPP_CorrectedReflectance_TrueColor is not served as PNG by GIBS
# so this is using JPEG tiles as source
# -outsize 65536 32768 took ~50 minutes
# -outsize 32768 16384 took ~15 minutes
# you can run multiple instances at once without issues to reduce total time
# TODO probably should be using a less detailed tileset than 250m to put
# less stress on the server...!
layer=VIIRS_SNPP_CorrectedReflectance_TrueColor
caldate=$1 # 2020-09-09
tilelevel=8 # 8 is the highest for 250m, see Capa -> 163840 81920 would be the full outsize
# 2022 says: Dude, check what gdal says for "Input file size is x, y" and then compare it to the outsize. Use the tilelevel that gives 2x the outsize, that seems to be what's needed
# ready? let's go!
gdal_translate \
-outsize 32768 16384 \
-projwin -180 90 180 -90 \
-of GTIFF \
-co TILED=YES \
-co COMPRESS=DEFLATE \
-co PREDICTOR=2 \
-co NUM_THREADS=ALL_CPUS \
"<GDAL_WMS>
<Service name=\"TMS\">
<ServerUrl>https://gibs.earthdata.nasa.gov/wmts/epsg4326/best/"${layer}"/default/"${caldate}"/250m/\${z}/\${y}/\${x}.jpg</ServerUrl>
</Service>
<DataWindow>
<UpperLeftX>-180.0</UpperLeftX><!-- makes sense -->
<UpperLeftY>90</UpperLeftY><!-- makes sense -->
<LowerRightX>396.0</LowerRightX><!-- wtf -->
<LowerRightY>-198</LowerRightY><!-- wtf -->
<TileLevel>"${tilelevel}"</TileLevel>
<TileCountX>2</TileCountX>
<TileCountY>1</TileCountY>
<YOrigin>top</YOrigin>
</DataWindow>
<Projection>EPSG:4326</Projection>
<BlockSizeX>512</BlockSizeX><!-- correct for VIIRS_SNPP_CorrectedReflectance_TrueColor-->
<BlockSizeY>512</BlockSizeY><!-- correct for VIIRS_SNPP_CorrectedReflectance_TrueColor -->
<BandsCount>3</BandsCount>
</GDAL_WMS>" \
${layer}-${caldate}.tif
As this was no scientific project, please note that I have spent no time checking e. g.:
If one could reduce the (significantly) compression artifacts of imagery received through this (the imagery is only provided as JPEG using this particular API),
if the temporal queries are actually getting the correct dates,
if there might be more imagery available
or even if the geographic referencing is correct.
As it takes a long time to fetch an image this way, I decided to go for a resolution of 32768×16384 pixels instead of 65536×32768 because the latter took about 50 minutes per image. A day of 32768×16384 pixels took me about 15 minutes to download.
Overlaying the images
There are lots of options to overlay images. imagemagick/graphicsmagick might be the obvious choice but they are unfit for imagery of these dimensions (exhausting RAM). VIPS/nips2 is awesome but might require some getting used to and/or manual processing. GDAL is the hot shit and very RAM friendly if you are careful. So I used GDAL for this.
Make sure to store the images somewhere sensible for lots of I/O.
Got all the images you want to process? Cool, build a VRT for them:
You can now use a median, mean, min or max function for aggregating the images per pixel. For that you have to modify the VRT to include the function you want it to use. I used sed for that:
That’s it, we are ready to use GDAL to build an image that combines all the daily images into one median image. For this to work you have to set the PYTHONPATH environment variable to include the directory of the functions.py file. If it is in the same directory where you launch gdal, you can use $PWD, otherwise enter the full path to the directory. Adjust the rest of the options as you like, e. g. to choose a different output format. If you use COG, enabling ALL_CPUS is highly recommended or building overviews will take forever.
This will take many hours. 35 hours for me on a Ryzen 3600 with lots of RAM and the images on a cheap SSD. The resulting file is about the same size as the single images (makes sense, doesn’t it) at ~800 megabytes.
Alternative, faster approach
A small note while we are at it: GDAL calculates overviews from the source data. And since we are using a custom VRT function here, on a lot of raster images, that takes a long time. To save a lot of that time, you can build the file without overviews first, then calculate them in a second step. With this approach they will be calculated from the final raster instead of the initial input which, when ever there is non-trivial processing involved, is way quicker:
This took “just” 10 hours for the initial raster and then an additional 11 seconds for the conversion COG and the building of overviews. And the resulting file is bit-by-bit identical to the one from the direct-to-COG approach. So one third of processing time for the same result. Nice!
Please do not consider a true representation of the typical weather or cloud cover throughout the year. The satellite takes the day imagery at local noon if I recall correctly so the rest of the day is not part of this “analysis”. I did zero plausibility or consistency checks. The data was probably reprojected multiple times through out the full (sensor->composite) pipeline. The composite is based on color alone, anything bright will lead to a white-ish color, be it snow, ice, clouds, algae, sand, …
It’s just some neat imagery to love our planet.
Update 2020-01-05
Added compression to GeoTIFF creation where useful, not sure how I missed that here. Reduces filesizes to 1/2 or 1/3 even.
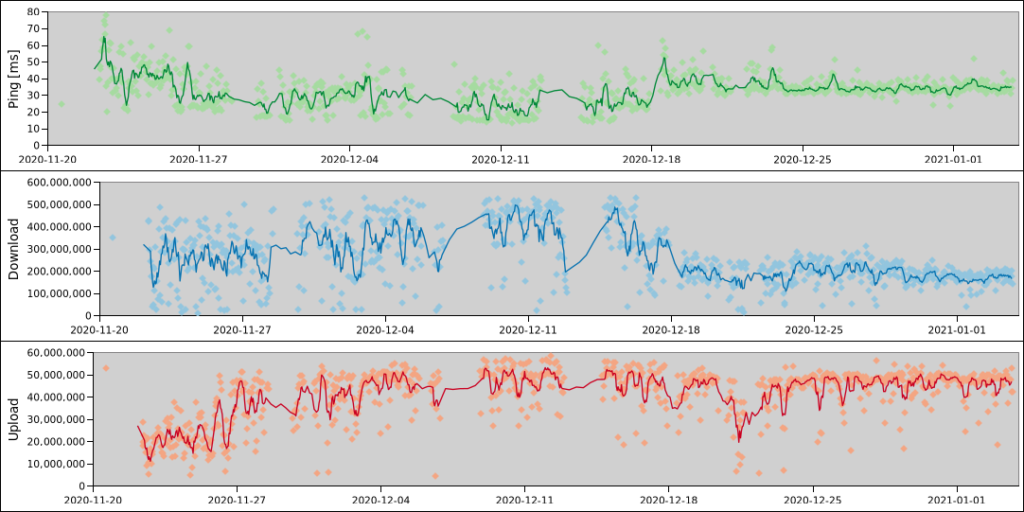
I wanted to monitor my ISP’s service over time and could not find any available simple tool for that. The usual system monitoring tools are usually displaying averages, not min/max values. So I used WD40 (speedtest-cli) and duct tape (cron) to make my own.
You need to have a cron daemon set up and speedtest-cli installed.
Then prepare an empty csv file with a header like this (don’t forget a trailing newline!) and store it in a path of your choice:
Server ID,Sponsor,Server Name,Timestamp,Distance,Ping,Download,Upload,Share,IP Address
Set up a cronjob at an interval of your choice (don’t be a dick) to run a speed test and log the results to the csv file:
If you have a fast connection you might spot slow test servers that would badly bias your results, so exclude them using the --exclude option if necessary.
That’s all, you get a nice log of internet ping, upload and download speeds, ready to be visualized in your software of choice (like the best spreadsheet software in existence). I will have to complain to my ISP for that drop since mid December for sure:
And now that I have written this, I realise that for plotting I could also just use a min/max function for a moving time window in Grafana I guess? The speedtests would still be triggered and provide nice bursts of usage. Anyone got pointers on how to do that?
Connect your Brother DCP-L2530DW to your WLAN/Wifi network. Find the printer’s IP (make sure it is static, e. g. by setting it up accordingly in your router). Adjust the IP in the lines below.
Scanning
Install brscan4 and xsane. As root run: brsaneconfig4 -a name="DCP-L2530DW" model="DCP-L2530DW" ip=192.168.1.123
PS: If you change the IP, you might need to edit /etc/opt/brother/scanner/brscan5/brsanenetdevice.cfg and /etc/cups/printers.conf.
For printing via USB (e.g. because you don’t want to have a 2.4GHz network anymore but this sad printer supports no 5GHz), simply install brother-dcp-l2530dw from AUR, “find new printers” in CUPS and add it.
Mediatheken des Öffentlich-rechtlichen Rundfunks müssen wegen asozialen Arschlöchern ihre Inhalte depublizieren. Wegen anderer Arschlöcher sind die Inhalte nicht konsequent unter freien Lizenzen, aber das ist ein anderes Thema.
Ich hatte mir irgendwann mal angesehen, was es eigentlich für ein Aufwand wäre, die Inhalte verschiedener Mediatheken in ein privates Archiv zu spiegeln. Mit dem Deutschlandradio hatte ich angefangen und mit den üblichen Tools täglich die neuen Audiobeiträge in ein Google Drive geschoben. Dieses Setup läuft jetzt seit mehr als 2 Jahren ohne Probleme und vielleicht hat ja auch wer anders Spaß dran:
Also:
rclone einrichten oder mit eigener Infrastruktur arbeiten (dann die rclone-Zeile mit z.B. rsync ersetzen)
<20 GB Platz haben
Untenstehendes Skript als täglichen Cronjob einrichten (und sich den Output zu mailen lassen)
#!/bin/bash
# exit if anything fails
# not a good idea as downloads might 404 :D
set -e
cd /home/dradio/deutschlandradio
# get all available files
wget -nv -nc -x "http://srv.deutschlandradio.de/aodlistaudio.1706.de.rpc?drau:page="{0..100}"&drau:limit=1000"
grep -hEo 'http.*mp3' srv.deutschlandradio.de/* | sort | uniq > urls
# check which ones are new according to the list of done files
comm -13 urls_done urls > todo
numberofnewfiles=$(wc -l todo | awk '{print $1}')
echo "${numberofnewfiles} new files"
if (( numberofnewfiles < 1 )); then
echo "exiting"
exit
fi
# get the new ones
echo "getting new ones"
wget -i todo -nv -x -nc || echo "true so that set -e does not exit here :)"
echo "new ones downloaded"
# copy them to remote storage
rclone copy /home/dradio_scraper/deutschlandradio remote:deutschlandradio && echo "rclone done"
## clean up
# remove files
echo "cleaning up"
rm -r srv.deutschlandradio.de/
rm -rv ondemand-mp3.dradio.de/
rm urls
# update list of done files
cat urls_done todo | sort | uniq > /tmp/urls_done
mv /tmp/urls_done urls_done
# save todo of today
mv todo urls_$(date +%Y%m%d)
echo "done"
Pro Tag sind es so 2-3 Gigabyte neuer Beiträge.
In zwei Jahren sind rund 2,5 Terabyte zusammengekommen und ~300.000 Dateien, aber da sind eventuell auch die Seiten des Feeds mitgezählt worden und Beiträge, die schon älter waren.
Wer mehr will nimmt am besten direkt die Mediathekview-Datenbank als Grundlage.
Nächster Schritt wäre das eigentlich auch täglich nach archive.org zu schieben.
I ran GDAL 2.4’s gdal_translate (GDAL 2.4.0dev-333b907 or GDAL 2.4.0dev-b19fd35e6f-dirty, I am not sure) on some GeoTIFFs to compare the new ZSTD compression support to DEFLATE in file sizes and time taken.
Hardware was a mostly idle Intel(R) Xeon(R) CPU E3-1245 V2 @ 3.40GHz with fairly old ST33000650NS (Seagate Constellation) harddisks and lots of RAM.
A small input file was DGM1_2x2KM_XYZ_HH_2016-01-04.tif with about 40,000 x 40,000 pixels at around 700 Megabytes.
A big input file was srtmgl1.003.tif with about 1,3000,000 x 400,000 pixels at 87 Gigabytes.
Both input files had been DEFLATE compressed at the default level 6 without using a predictor (that’s what the default DEFLATE level will make them smaller here).
gdal_translate -co NUM_THREADS=ALL_CPUS -co PREDICTOR=2 -co TILED=YES -co BIGTIFF=YES --config GDAL_CACHEMAX 6144 was used all the time.
For DEFLATE -co COMPRESS=DEFLATE -co ZLEVEL=${level} was used, for ZSTD -co COMPRESS=ZSTD -co ZSTD_LEVEL=${level}
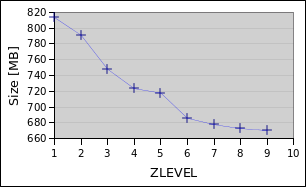
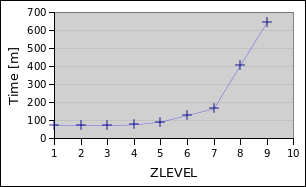
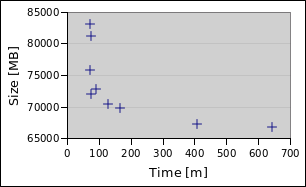
Mind the axes, sometimes I used a logarithmic scale!
Small file
DEFLATE
ZSTD
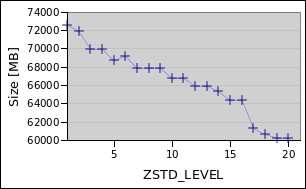
Big file
DEFLATE
ZSTD
Findings
It has been some weeks since I really looked at the numbers, so I am making the following up spontaneously. Please correct me!
Those numbers in the findings below should be percentages (between the algorithms, to their default values, etc), but my curiosity was satisfied. At the bottom is the data, maybe you can take it to present a nicer evaluation? ;)
ZSTD is powerful and weird. Sometimes subsequent levels might lead to the same result, sometimes a higher level will be fast or bigger. On low levels it is just as fast as DEFLATE or faster with similar or smaller sizes.
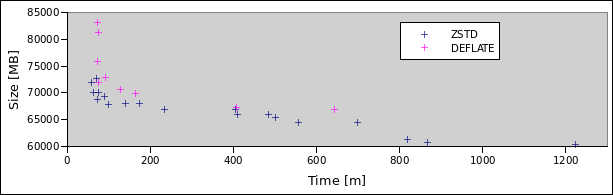
A <700 Megabyte version of the small file was accomplished within a minute with DEFLATE (6) or half a minute with ZSTD (5). With ZSTD (17) it got down to <600 Megabyte in ~5 Minutes, while DEFLATE never got anywhere near that.
Similarly for the big file, ZSTD (17) takes it down to 60 Gigabytes but it took almost 14 hours. DEFLATE capped at 65 Gigabytes. The sweet spot for ZSTD was at 10 with 4 hours for 65 Gigabytes (DEFLATE took 11 hours for that).
In the end, it is hard to say what default level ZSTD should take. For the small file level 5 was amazing, being even smaller than and almost twice as fast as the default (9). But for the big file the gains are much more gradual, here level 3 or level 10 stand out. I/O might be to blame?
Yes, the machine was not stressed and I did reproduce those weird ones.
translates “so center of mass is at (0,0,0)” and scales to something smaller and rotates so that z is up. trimesh2’s documentation on the rot parameter is insufficient, I think my solution means “rotate by 90 degrees -1 times around x, 0 times around y, 0 times around z” or something like that. Look into the source if that helps you.