For audiobooks use Opus with a low bitrate of 16 kbps and the Additional encoder argument -ac 1 for mono.
Copy directory structure will create full path directories in the destination directory, e.g. if you convert /home/foo/music/ to /tmp/, it will create the output in /tmp/home/foo/music/.
For future updates: Select the same directories, fix the xml again, make sure that Settings -> General -> Conversion -> Conflict Handling is set to “Skip File”.
I did not manage to put the display directly on top of the Pico as a hat. Also my display’s board has its pins numbered and labelled mirrored when comparing to the official pin out. FFS…!?
Install pico-sdk and thonny from AUR.
$ sudo usermod -a -G uucp $USER
Reboot.
Make sure you aren’t full of static electricity. Hold the BOOTSEL button on your PI and connect it to your PC using a USB cable.
It should appear as storage device.
Start Thonny, select “Micropython (Raspberry Pi Pico)” as interpreter and use its “Install or update MicroPython” option. This does that “copy some RPI_PICO-20231005-v1.21.0.uf2 file to your Pico in mass storage mode” step for you.
The Thonny shell should say something like:
MicroPython v1.21.0 on 2023-10-06; Raspberry Pi Pico with RP2040
Type "help()" for more information.
>>>
Enter the following code in your Thonny shell (via):
from machine import Pin
led = Pin(25, Pin.OUT)
led.on()
The Pico’s green LED should glow now. Use led.off() to turn it off again.
Unplug your Pico. Make sure you aren’t full of static electricity.
echo 0 | tee /sys/devices/system/cpu/cpufreq/boost
Might work, might not, depending on unknown factors. Whatever, I just wanted to make some all-core-but-unimportant process to run without going 95°C. For that it worked perfectly well. CPU temps of a Ryzen 5 3600 after many hours of full utilization were at ~65°C. CPU frequencies were capped to 3.6GHz with this while jumping up to 4.2GHz (and ~94°C) without.
Obviously this has an impact on performance.
To re-enable just echo a 1 instead. This is reset anyways when you reboot your system.
Raster Image Marker with https://opengameart.org/content/character-spritesheet-duck, vertical anchor at bottom, sprite choice between walking and running (doesn’t actually work) plus the frame via
As I will shut it down (no reason, just decluttering) here’s how it works so you can run your own:
Have aerial images with a permissive license
Register a Twitter account and set it up for posting via API access
Write code to pick an image and post it
Done!
Okok, I am kidding.
I used https://suche.transparenz.hamburg.de/dataset/digitale-orthophotos-belaubt-hamburg3 as data source because they have a CC-BY like license, allowing such a project without any legal complications. As a side benefit these images are already provided in tiles: There is not one big image of the whole region but 1km² image tiles. Perfect for random selection, quick resizing and posting.
Registering a Twitter account and setting it up is a privacy nightmare and, being a good human being as you are, you ought hate any part of it. I followed the Twython tutorial for OAuth1 in a live Python interpreter session which was fairly painless. If you do not want to link a phone number to your Twitter account (see above for how you should feel about that), this approach worked for me in the past but I bet they use regional profiling or worse so your luck might differ.
Next you need some code to do the work for you automatically. Here is what I wrote with Pillow==7.0.0 for the image processing and twython==3.8.2 for posting:
import glob
import random
from io import BytesIO
from PIL import Image
from twython import Twython
## Initialise Twitter
# use a Python interpreter to follow the stops on
# https://twython.readthedocs.io/en/latest/usage/starting_out.html#oauth-1-user-authentication
# don't rush, there are some intermediate keys iirc...
APP_KEY = '1234567890ABCDEFGHIJKLMNO'
APP_SECRET = '12345678901234567890123456F8U0CAKATAWAIATATAEARAAA'
OAUTH_TOKEN = '1234567890123456789123456F8U0CAKATAWAIATATAEARAAAA'
OAUTH_TOKEN_SECRET = '123456789012345678901234567890FFSFFSFFSFFSFFS'
twitter = Twython(APP_KEY, APP_SECRET, OAUTH_TOKEN, OAUTH_TOKEN_SECRET)
## Prepare the image
# via https://twython.readthedocs.io/en/latest/usage/advanced_usage.html#posting-a-status-with-an-editing-image
# Pick the image
jpegs = glob.glob("DOP20_HH_sommerbefliegung_2019.zip/*.jpg")
todays_image = random.choice(jpegs)
print(f"Today we will post {todays_image}")
photo = Image.open(todays_image)
# Resize the image
basewidth = 1000
wpercent = (basewidth / float(photo.size[0]))
height = int((float(photo.size[1]) * float(wpercent)))
resized_photo = photo.resize((basewidth, height), Image.ANTIALIAS)
# "Save" the resulting image in temporary memory
stream = BytesIO()
resized_photo.save(stream, format='JPEG')
stream.seek(0)
## We've got what we need, let's tweet
license = "dl-de/by-2-0 (Freie und Hansestadt Hamburg, Landesbetrieb Geoinformation und Vermessung)"
tweet = f"Das ist #IrgendwoInHH, aber wo denn nur?\n\n#codeforhamburg\n\nBild: {license}"
response = twitter.upload_media(media=stream)
twitter.update_status(status=tweet, media_ids=[response['media_id']])
First we initialize that Twython thingie, then we pick a random image from a directory of .jpg files, then we resize it to a maximum of 1000 pixels (you can simplify that if your images are square…) and finally we post it to Twitter.
Set up a cronjob or systemd timer or alarm clock to run the script as often as you like and that’s it.
A follow-up to Average Earth from Space 2018 with a how-to. For each day of 2020 I took one global true color image of the whole planet and merged them together by using the most typical color per pixel. You can see cloud patterns in astonishing detail, global wind, permafrost (careful, white can be ice and/or clouds here) and more. Scroll to the bottom for interactive full resolution viewers.
Basically we will want to overlay one satellite image per day into one image for the whole year. You need two things: The images and the GDAL suite of geospatial processing tools.
set -e
set -u
# run like: $ bash gibs_viirs.sh 2020-10-05
# you get: VIIRS_SNPP_CorrectedReflectance_TrueColor-2020-10-05.tif
# in ~15 minutes and at ~600 megabytes for 32768x16384 pixels
# based on https://gist.github.com/jscarto/6c0413f4820ed5141744e96e19f31205
# https://gibs.earthdata.nasa.gov/wmts/epsg4326/best/1.0.0/WMTSCapabilities.xml
# VIIRS_SNPP_CorrectedReflectance_TrueColor is not served as PNG by GIBS
# so this is using JPEG tiles as source
# -outsize 65536 32768 took ~50 minutes
# -outsize 32768 16384 took ~15 minutes
# you can run multiple instances at once without issues to reduce total time
# TODO probably should be using a less detailed tileset than 250m to put
# less stress on the server...!
layer=VIIRS_SNPP_CorrectedReflectance_TrueColor
caldate=$1 # 2020-09-09
tilelevel=8 # 8 is the highest for 250m, see Capa -> 163840 81920 would be the full outsize
# 2022 says: Dude, check what gdal says for "Input file size is x, y" and then compare it to the outsize. Use the tilelevel that gives 2x the outsize, that seems to be what's needed
# ready? let's go!
gdal_translate \
-outsize 32768 16384 \
-projwin -180 90 180 -90 \
-of GTIFF \
-co TILED=YES \
-co COMPRESS=DEFLATE \
-co PREDICTOR=2 \
-co NUM_THREADS=ALL_CPUS \
"<GDAL_WMS>
<Service name=\"TMS\">
<ServerUrl>https://gibs.earthdata.nasa.gov/wmts/epsg4326/best/"${layer}"/default/"${caldate}"/250m/\${z}/\${y}/\${x}.jpg</ServerUrl>
</Service>
<DataWindow>
<UpperLeftX>-180.0</UpperLeftX><!-- makes sense -->
<UpperLeftY>90</UpperLeftY><!-- makes sense -->
<LowerRightX>396.0</LowerRightX><!-- wtf -->
<LowerRightY>-198</LowerRightY><!-- wtf -->
<TileLevel>"${tilelevel}"</TileLevel>
<TileCountX>2</TileCountX>
<TileCountY>1</TileCountY>
<YOrigin>top</YOrigin>
</DataWindow>
<Projection>EPSG:4326</Projection>
<BlockSizeX>512</BlockSizeX><!-- correct for VIIRS_SNPP_CorrectedReflectance_TrueColor-->
<BlockSizeY>512</BlockSizeY><!-- correct for VIIRS_SNPP_CorrectedReflectance_TrueColor -->
<BandsCount>3</BandsCount>
</GDAL_WMS>" \
${layer}-${caldate}.tif
As this was no scientific project, please note that I have spent no time checking e. g.:
If one could reduce the (significantly) compression artifacts of imagery received through this (the imagery is only provided as JPEG using this particular API),
if the temporal queries are actually getting the correct dates,
if there might be more imagery available
or even if the geographic referencing is correct.
As it takes a long time to fetch an image this way, I decided to go for a resolution of 32768×16384 pixels instead of 65536×32768 because the latter took about 50 minutes per image. A day of 32768×16384 pixels took me about 15 minutes to download.
Overlaying the images
There are lots of options to overlay images. imagemagick/graphicsmagick might be the obvious choice but they are unfit for imagery of these dimensions (exhausting RAM). VIPS/nips2 is awesome but might require some getting used to and/or manual processing. GDAL is the hot shit and very RAM friendly if you are careful. So I used GDAL for this.
Make sure to store the images somewhere sensible for lots of I/O.
Got all the images you want to process? Cool, build a VRT for them:
You can now use a median, mean, min or max function for aggregating the images per pixel. For that you have to modify the VRT to include the function you want it to use. I used sed for that:
That’s it, we are ready to use GDAL to build an image that combines all the daily images into one median image. For this to work you have to set the PYTHONPATH environment variable to include the directory of the functions.py file. If it is in the same directory where you launch gdal, you can use $PWD, otherwise enter the full path to the directory. Adjust the rest of the options as you like, e. g. to choose a different output format. If you use COG, enabling ALL_CPUS is highly recommended or building overviews will take forever.
This will take many hours. 35 hours for me on a Ryzen 3600 with lots of RAM and the images on a cheap SSD. The resulting file is about the same size as the single images (makes sense, doesn’t it) at ~800 megabytes.
Alternative, faster approach
A small note while we are at it: GDAL calculates overviews from the source data. And since we are using a custom VRT function here, on a lot of raster images, that takes a long time. To save a lot of that time, you can build the file without overviews first, then calculate them in a second step. With this approach they will be calculated from the final raster instead of the initial input which, when ever there is non-trivial processing involved, is way quicker:
This took “just” 10 hours for the initial raster and then an additional 11 seconds for the conversion COG and the building of overviews. And the resulting file is bit-by-bit identical to the one from the direct-to-COG approach. So one third of processing time for the same result. Nice!
Please do not consider a true representation of the typical weather or cloud cover throughout the year. The satellite takes the day imagery at local noon if I recall correctly so the rest of the day is not part of this “analysis”. I did zero plausibility or consistency checks. The data was probably reprojected multiple times through out the full (sensor->composite) pipeline. The composite is based on color alone, anything bright will lead to a white-ish color, be it snow, ice, clouds, algae, sand, …
It’s just some neat imagery to love our planet.
Update 2020-01-05
Added compression to GeoTIFF creation where useful, not sure how I missed that here. Reduces filesizes to 1/2 or 1/3 even.
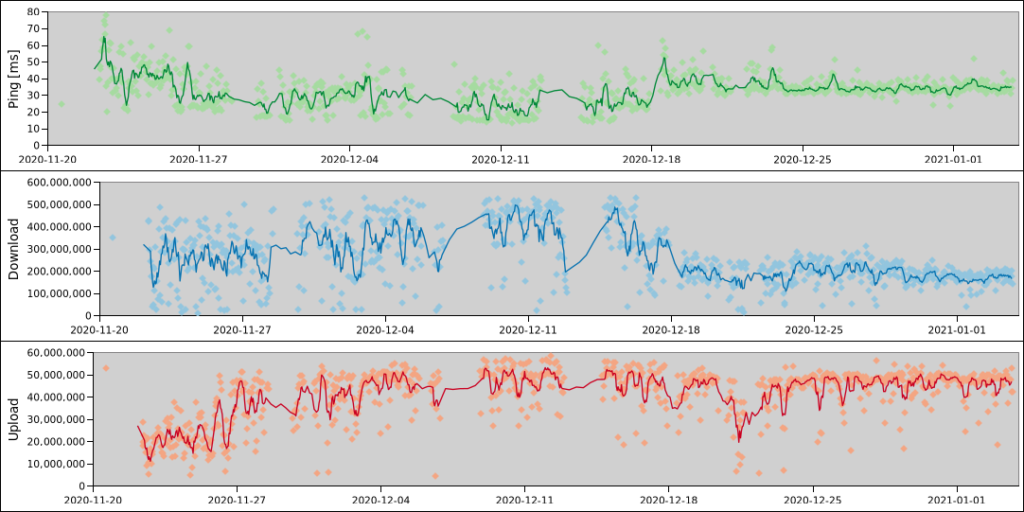
I wanted to monitor my ISP’s service over time and could not find any available simple tool for that. The usual system monitoring tools are usually displaying averages, not min/max values. So I used WD40 (speedtest-cli) and duct tape (cron) to make my own.
You need to have a cron daemon set up and speedtest-cli installed.
Then prepare an empty csv file with a header like this (don’t forget a trailing newline!) and store it in a path of your choice:
Server ID,Sponsor,Server Name,Timestamp,Distance,Ping,Download,Upload,Share,IP Address
Set up a cronjob at an interval of your choice (don’t be a dick) to run a speed test and log the results to the csv file:
If you have a fast connection you might spot slow test servers that would badly bias your results, so exclude them using the --exclude option if necessary.
That’s all, you get a nice log of internet ping, upload and download speeds, ready to be visualized in your software of choice (like the best spreadsheet software in existence). I will have to complain to my ISP for that drop since mid December for sure:
And now that I have written this, I realise that for plotting I could also just use a min/max function for a moving time window in Grafana I guess? The speedtests would still be triggered and provide nice bursts of usage. Anyone got pointers on how to do that?
Mediatheken des Öffentlich-rechtlichen Rundfunks müssen wegen asozialen Arschlöchern ihre Inhalte depublizieren. Wegen anderer Arschlöcher sind die Inhalte nicht konsequent unter freien Lizenzen, aber das ist ein anderes Thema.
Ich hatte mir irgendwann mal angesehen, was es eigentlich für ein Aufwand wäre, die Inhalte verschiedener Mediatheken in ein privates Archiv zu spiegeln. Mit dem Deutschlandradio hatte ich angefangen und mit den üblichen Tools täglich die neuen Audiobeiträge in ein Google Drive geschoben. Dieses Setup läuft jetzt seit mehr als 2 Jahren ohne Probleme und vielleicht hat ja auch wer anders Spaß dran:
Also:
rclone einrichten oder mit eigener Infrastruktur arbeiten (dann die rclone-Zeile mit z.B. rsync ersetzen)
<20 GB Platz haben
Untenstehendes Skript als täglichen Cronjob einrichten (und sich den Output zu mailen lassen)
#!/bin/bash
# exit if anything fails
# not a good idea as downloads might 404 :D
set -e
cd /home/dradio/deutschlandradio
# get all available files
wget -nv -nc -x "http://srv.deutschlandradio.de/aodlistaudio.1706.de.rpc?drau:page="{0..100}"&drau:limit=1000"
grep -hEo 'http.*mp3' srv.deutschlandradio.de/* | sort | uniq > urls
# check which ones are new according to the list of done files
comm -13 urls_done urls > todo
numberofnewfiles=$(wc -l todo | awk '{print $1}')
echo "${numberofnewfiles} new files"
if (( numberofnewfiles < 1 )); then
echo "exiting"
exit
fi
# get the new ones
echo "getting new ones"
wget -i todo -nv -x -nc || echo "true so that set -e does not exit here :)"
echo "new ones downloaded"
# copy them to remote storage
rclone copy /home/dradio_scraper/deutschlandradio remote:deutschlandradio && echo "rclone done"
## clean up
# remove files
echo "cleaning up"
rm -r srv.deutschlandradio.de/
rm -rv ondemand-mp3.dradio.de/
rm urls
# update list of done files
cat urls_done todo | sort | uniq > /tmp/urls_done
mv /tmp/urls_done urls_done
# save todo of today
mv todo urls_$(date +%Y%m%d)
echo "done"
Pro Tag sind es so 2-3 Gigabyte neuer Beiträge.
In zwei Jahren sind rund 2,5 Terabyte zusammengekommen und ~300.000 Dateien, aber da sind eventuell auch die Seiten des Feeds mitgezählt worden und Beiträge, die schon älter waren.
Wer mehr will nimmt am besten direkt die Mediathekview-Datenbank als Grundlage.
Nächster Schritt wäre das eigentlich auch täglich nach archive.org zu schieben.
Did this for an ex-colleague some months ago and forgot to share the how-to publically. We needed a visual representation of the current time in a layout that showed both a raster map (different layer per timeslice) and a timeseries plot of an aspect of the data (this was created outside QGIS).
Have lots of raster layers you want to iterate through. I have:
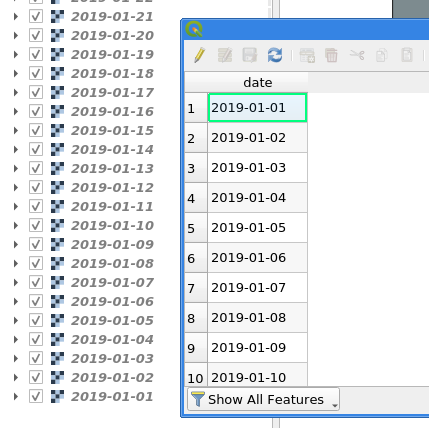
Create a new layer for your map extent. Draw your extent as geometry. Duplicate that geometry as many times as you have days. Alternatively you could of course have different geometries per day. Whatever you do, you need a layer with one feature per timeslice for the Atlas to iterate though. I have 30 days to visualise so I duplicated my extent 30 times.
Open the Field Calculator. Add a new field called date as string type (not as date type until some bug is fixed (sorry, did not make a note here, maybe sorting is/was broken?)) with an expression that represents time and orders chronologically if sorted by QGIS. For example: '2019-01-' || lpad(@row_number,2,0) (assuming your records are in the correct order if you have different geometries…)
Have your raster layers named the same way as the date attribute values.
Make a new layout.
For your Layout map check “Lock layers” and use date as expression for the “Lock layers” override. This will now select the appropriate raster layer, based on the attribute value <-> layer name, to display for each Atlas page.
Cool, if you preview the Atlas now you got a nice animation through your raster layers. Let’s do part 2:
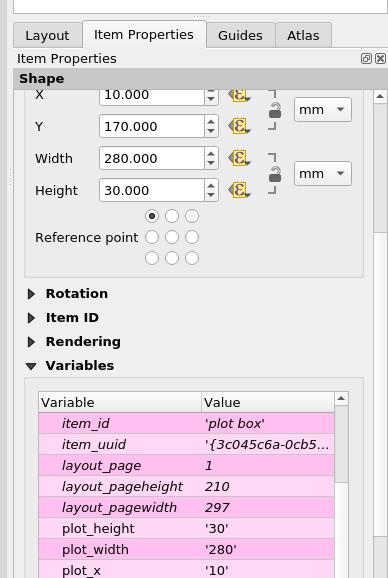
In your layout add your timeseries graph. Give it a unique ID, e. g. “plot box”. Set its width and height via new variables (until you can get those via an expression this is needed for calculations below).
Create a box to visualise the timeslice. Set its width to map_get(item_variables('plot box'), 'plot_width') / @atlas_totalfeatures. For the height and y use/adjust this expression: map_get(item_variables('plot box'), 'plot_height'). For x comes the magic:
with_variable( 'days_total', day(to_date(maximum("date"))-to_date(minimum("date")))+1, -- number of days in timespan -- +1 because we need the number of days in total -- not the inbetween, day() to just get the number of days with_variable( 'mm_per_day', map_get(item_variables('plot box'), 'plot_width') / @days_total, with_variable( 'days', day(to_date(attribute(@atlas_feature, 'date'))-to_date(minimum("date"))), -- number of days the current feature is from the first day -- to_date because BUG attribute() returns datetime for date field @mm_per_day * @days + map_get(item_variables('plot box'), 'plot_x') ) ) )
This will move the box along the x axis accordingly.
Add a “Geometry Generator” to the same layer and set it to “LineString / MultiLineString”. If you used polygons, you will need to use “boundary($geometry)” to get the border lines of your polygons.
Translate (shift) the geometries radially away from the map center, with an amount of translation based on their distance to the map center. This will introduce ugly artifacts cool glitches for big geometries. Note the magic constant of 150 I divided the distances by, I cannot be arsed to turn this into percentages so you will have to figure out what works for you. Also, if your map is in a different CRS than the layer you do this with, you will need to transform the coordinates (I do that for the labels below).
Color those lines in some fancy 80s color like #00FFFF.
We only want the color to appear in the edges of the map, so set the “Feature Blending” mode of the layer to “Lighten”. This will make sure the white lines do not get darker/colored.
I forgot to take an image for that and then it was lunch time. :x
Now do the same but for distances the other way around and color that in something else (like foofy #FF00FF).
Oh, can you see it already? Move the map around! Ohhh!
For the final touch, use the layer’s “Draw Effects” to replace the “Source” with a “Blur”. Be aware that the “Blur type” can quite strongly influence the look and find a setting for the “Blur strength” that works for you. I used “Guassian blur (quality)” with a strength of 2.
Dynamic Label Shadows
Get some data to label! I used ne_10m_populated_places_simple. Label it with labels placed “Offset from Point” without any actual offset. This is just to make sure calculations on the geometry’s location make sense to affect the labeling later.
Add a “Buffer” to the labels and pick an appropriate color (BIG BOLD #FF00FF works well again).
Time for magic! Add a “Shadow” to the labels and use an appropriate color (I used the other color from earlier again, #00FFFF).
We want to make the label shadows be further away from the label if the feature is further away from the map center. So OVERRIDE the offset with code that does exactly that. Note another magic constant (relating to meters in EPSG:25832) and that I needed to transform coordinates here (my map is in EPSG:25832 while this layer is EPSG:4326).
Cool. But that just looks weird. Time for another magical ingredient while OVERRIDING the angle at which the label is placed. You guessed it, radially away from the map center!


























{kind=link}