Die HomepageJeder Eintrag im Transparenzportal Hamburg wurde gespieltMan konnte Suchen speichern und bei neuen Ergebnissen eine Mail erhalten
Ein Beispiel für einen EintragEin Eintrag mit mehreren verknüpften Resourcen
Die Idee war ursprünglich, dass dort Kommentare und Diskussionen zu den im Transparenzportal Hamburg (TPHH) veröffentlichten Datensätzen gepostet werden könnten. Und das vielleicht sogar direkt im TPHH eingebettet.
Dazu hat ein Python-Skript (als Bot namens “Heidi Kabel” ;) ) jede Minute die API des TPHH nach neuen Datensätzen gefragt, die Metadaten abgerufen und sie schön formatiert und aufbereitet als Foren-Threads gepostet. Ein spaßiges Bastel-Projekt, irgendwann 2019.
Die Dokumentation für die Forumsinstallation und der Code für den Bot liegen in:
Naja, dann kam Corona und Treffen von Code for Hamburg gab’s eh schon kaum noch. Die Seite hat praktisch niemand außer mir genutzt, es gab keine 10 Posts, die nicht vom Bot waren. Mit der Einbindung im TPHH wurde es auch nichts (ich hatte mich aber auch nicht drum gekümmert).
“Angesagte” Posts mit vielen Views
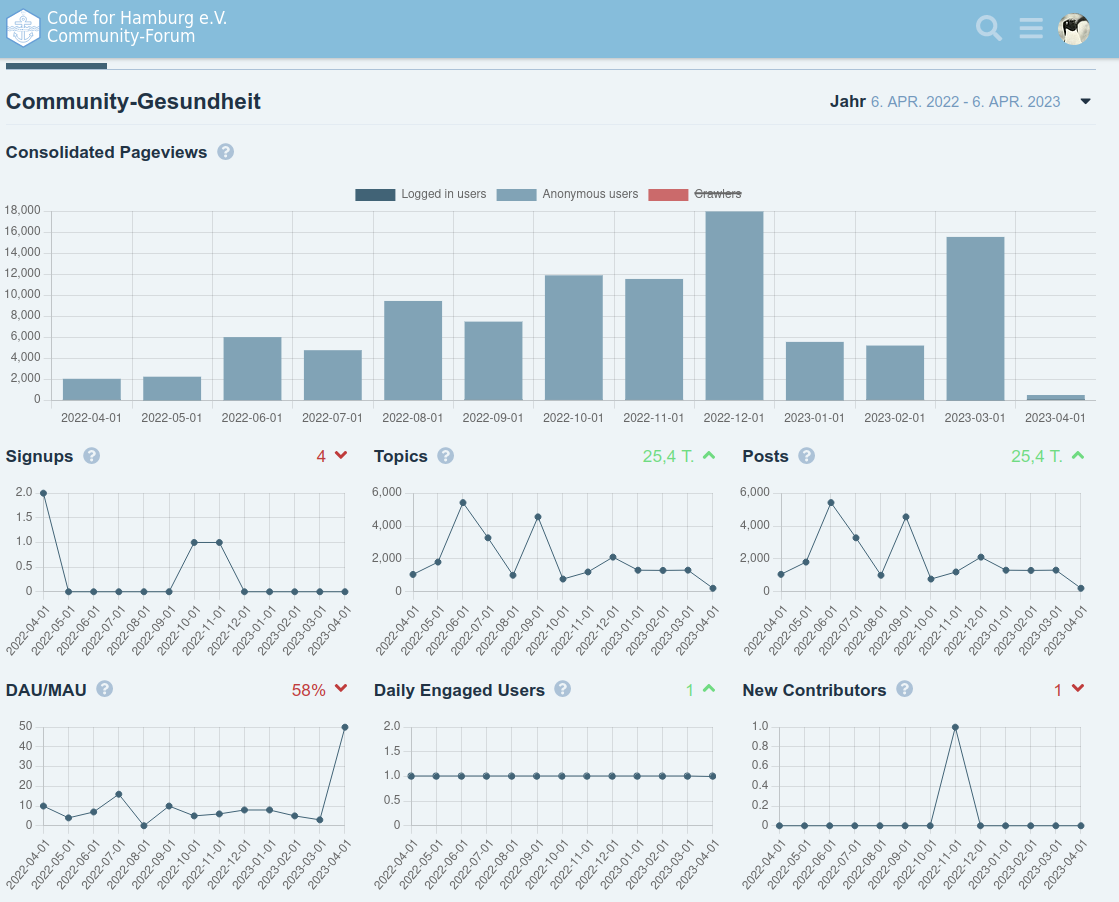
Pageviews exklusive (erkannte) CrawlerTop Referred Topics (keine Ahnung wo sie verlinkt wurden)
Der tägliche User war unser TPHH-Spiegel-Bot, die Posts/Topics auch
Ich hatte es für mich selbst noch als einfaches Interface für die Daten und als praktischen Benachrichtigungsservice auf bestimmte Keywords genutzt, aber jetzt klappt das Update der Forensoftware nicht mehr (Bug von Discourse mit angeblich nicht mehr einzigartigen Tags und es gab keine Rückmeldung auf meine Fragen, von daher …) und ich will da nix auf veralteter Software laufen lassen. Übernehmen wollte es niemand aus dem Verein und im Fediverse hat sich auch niemand gemeldet. Von daher mach ich die Tage das Licht aus.
PS: Ich hoffe Code for Hamburg wird irgendwann mal wieder reaktiviert, mit regelmäßigen Treffen, wo gehackt und gebastelt wird. Toi toi toi!
https://suche.transparenz.hamburg.de.EXAMPLE.COM/api/action/resource_search?query=url: (“.EXAMPLE.COM” entfernen) liefert aktuell rund 200 Megabyte an JSON, da sollten alle Resourcen drin stecken oder zumindest die, die tatsächlich einen Datensatz referenzieren
Um es in normalen Editoren besser handlebar zu machen, hilft json_pp:
Egal. Das ist ja großartig! Da werden eine Menge von Anwendungen ermöglicht (Sichtachsen! Verschattungen! Vermaschung! VR! AR!) und verschiedenste Akteure werden die Daten absolut feiern. Auch wenn es mit 1 Meter Auflösung wirklich mies grob ist, auf ein 1 Meter Gitter gerastert ist (nicht ausgedünnt, d. h. es ist teilweise stärker verfälscht und “daneben”) und “nur” bildbasiert (nicht gescannt) ist, geht da schon einiges mit.
Ausprobieren! Im Browser!
Achtung, frickelige Bedienung! Am besten den WASD-Möwen-Modus nutzen, mit Speed 1000. Oder mit einem Doppelklick irgendwo hinzoomen.
Für 2018 liegen die Daten als 12768 einzelne XYZ-Kacheln vor, also als super ineffiziente Textdateien. Insgesamt sind es rund 22 Gigabyte. Für 2020 sind es stattdessen 827 größere Kacheln, aber ebenfalls in XYZ mit einem ähnlichem Platzbedarf.
Schönerweise gibt es freie Tools wie LAStools‘ txt2las, was sie schnell und einfach ins super effiziente LAZ-Format umwandeln kann:
und 4 Minuten später ist die interaktive 3D-Webanwendung fertig, wegen der zusätzlichen Octree-Struktur jetzt bei rund 3 Gigabyte.
Punktwolke mit Farben aus Orthophoto einfärben
Die bereitgestellten Oberflächenmodelle sind so schlicht wie es nur geht, es sind reine XYZ-Daten ohne weitere Dimensionen wie Farbe o. ä.
Glücklicherweise gibt es ja auch die Orthophotos, eventuell wurde sogar dasselbe Bildmaterial genutzt? Da müsste mal jemand durch den Datenwust wühlen, die bei den DOPs werden die relevanten Metadaten nicht mitgeliefert…
Theoretisch könnte man sie also einfärben. Leider ist lascolor proprietär und kommt mit gruseligen, bösartigen Optionen, wenn man es wagt es “unlizenziert” zu nutzen (“Please note that the unlicensed version will (…) slightly change the LAS point order, and randomly add a tiny bit of white noise to the points coordinates once you exceed a certain number of points in the input file.”) und kann JPEG in GeoTIFF nicht lesen (so hab ich mir die DOPs aufbereitet). Eine Alternative ist das geniale PDAL. Mit einer Pipeline wie
ist die Punktwolke innerhalb von Minuten coloriert und kann dann wie gehabt mit PotreeConverter in einen interaktiven 3D-Viewer gesteckt werden.
Update 2023: "minor_version": "2" -> "minor_version": "4", damit LAS 1.4 rauskommt, um dann einfach COPC draus bauen zu können (Farben als 16-Bit, nicht 8-Bit). Und entsprechend noch ein Filter, um die Farben auf den 16-Bit-Wertebereich zu skalieren, das passiert leider nicht automatisch.
Das Ergebnis ist besser als erwartet, da es scheinbar tatsächlich die selben Bilddaten sind (für beide Jahre). Andererseits ist es auch nicht wirklich schick, da die DOPs nicht als True Orthophoto vorliegen und damit höhere Gebäude gekippt in den Bilder abgebildet sind. Sieht man hier schön am Planetarium.
Cloud-Optimized Point Cloud
Als Cloud-Optimized Point Cloud umwandeln kann man das Resultat einfach mit untwine (mit pdal pipeline braucht man immens viel RAM (>64GB), da die Umwandlung nach COPC hier nicht den Streaming Mode nutzen kann):
Anschließend auf einem Server (mit entsprechenden Access-Control-Allow-Headern) gelagert, kann die Punktwolke super einfach mit https://viewer.copc.io/?resources=https://example.com/pointcloud.copc.laz im Browser verwendet werden. Ganz ohne Umwandlung in viele Unterdateien wie beim PotreeConverter.
DOM als GeoTIFF
Wer es lieber als GeoTIFF haben möchte, hat es etwas schwerer, denn GDAL kommt mit dieser Art von Kacheln (mit Lücken und in der bereitgestellten Sortierung) nicht gut klar. Mein Goto-Tool dafür ist GMT.
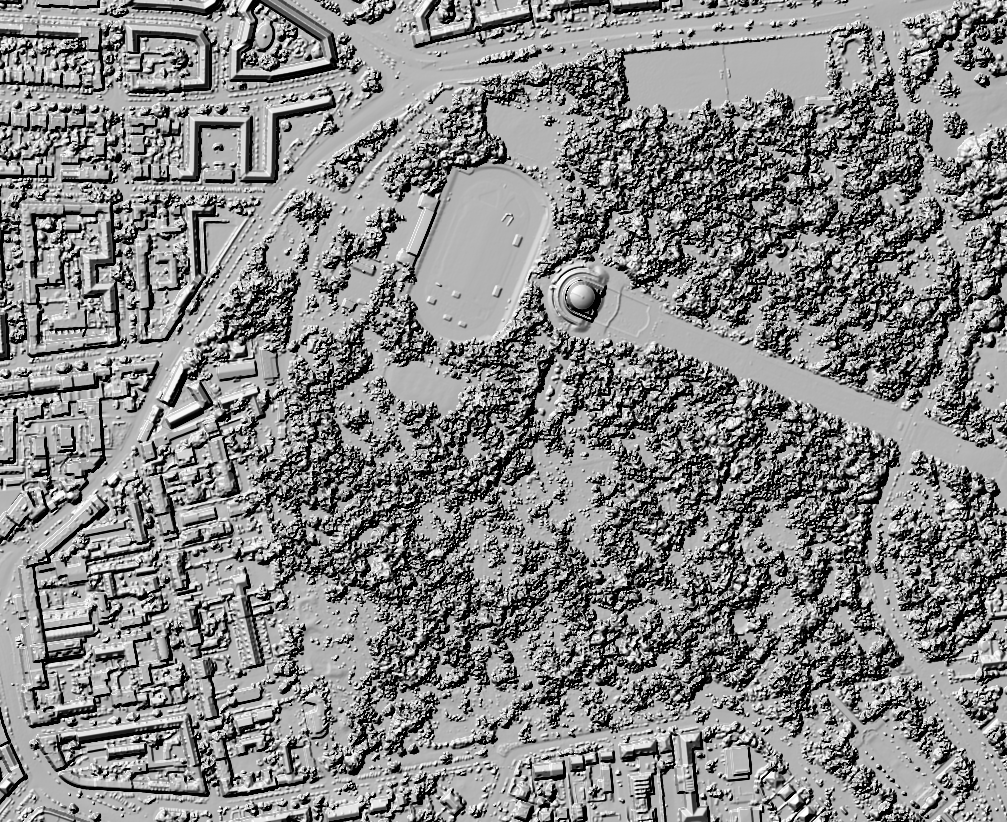
Hier mal im Vergleich mit dem DGM1 als Schummerungen:
Vermaschung als 3D-Modell
Leider habe ich keine gute Lösung für die 3D-Vermaschung gefunden. tin-terrain und dem2mesh kommen nicht mit so großen Datenmengen auf einmal klar und weiter hab ich nicht geschaut. Wer da was gutes weiß kann sich bei mir bei nächster Gelegenheit Kekse oder Bier abholen. ;)
Daten hinter den Bildern und den Viewern Datenlizenz Deutschland Namensnennung 2.0, Freie und Hansestadt Hamburg, Landesbetrieb Geoinformation und Vermessung (LGV)
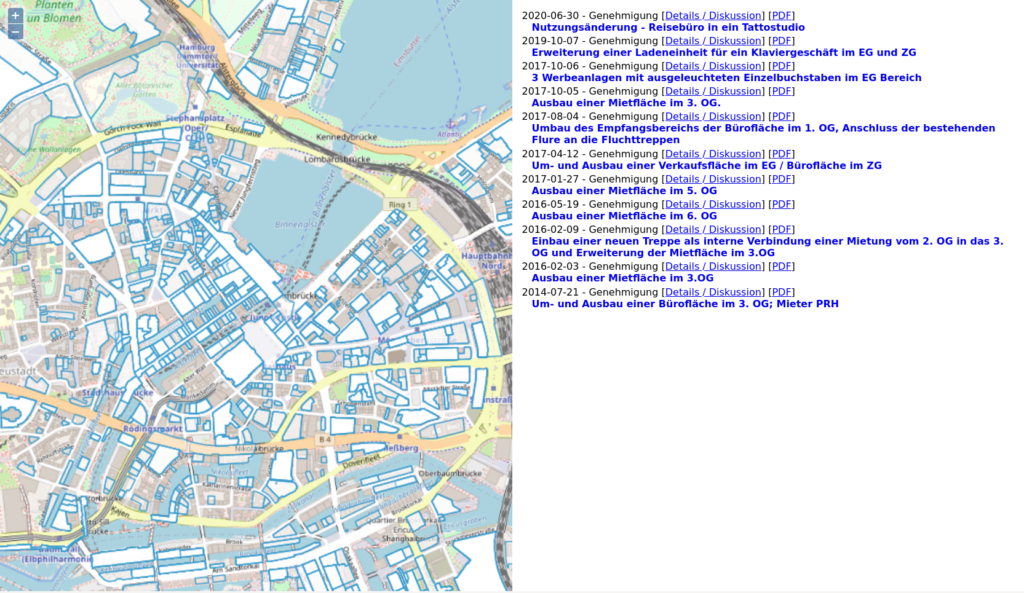
Je weniger transparent eine Fläche dargestellt ist, desto mehr Dokumente sind mit ihr verknüpft (ja, es ist ein Feature je Dokument D;). Eigentlich war die Seite anders aufgebaut, mit einem PDF-Viewer auf der rechten Seite. Aber da daten.transparenz.hamburg.de kein HTTPS kann (seid ihr auch so gespannt auf die UMTS-Auktion nächste Woche?), geht das aus Sicherheitsgründen nicht ohne ein Spiegeln der Daten oder einen Proxy.
Die Daten kommen größtenteils aus dem Transparenzportal. Für das Matching der angebenen Flurstücks-“IDs” zu den tatsächlichen Flurstücken war aber ein erheblicher Aufwand nötig. Das Drama ging bis hin zum Parsen aus PDFs, die mal so, mal so formatiert waren und natürlich auch voller Eingabefehler auf Behördenseite. Vielleicht schreibe ich da noch beizeiten mal einen Rant. TL;DR: Ohne die zugehörige Gemarkung ist mit einer Flurstücks-“ID” wie in den Daten angegeben keine räumliche Zuordnung möglich. In den veröffentlichten Daten stecken nur die Nenner der Flurstücksnummern, nicht aber die Gemarkungsnummern. Ziemlich absurd.
Das ganze ist nur ein Prototyp, vermutlich voller Fehler und fehlender Daten. Aber interessant und spaßig ist es, viel Freude also!
Es wäre noch eine MENGE zu tun, um das ganze rund zu machen. Falls du Lust hast, melde dich gerne. Es geht vom wilden Parsen, über Sonderregeln für kaputte Dokumente, zu Kartenstyling bis zur UI. Schön wäre es auch alles in einer anständigen Datenbank zu halten und nicht nur nach der räumlichen Dimension durchsuchen zu können.
Let’s take it to the next level: Wir wollen alle auf daten-hamburg.de gehosteten Datensätze, weil da die ganzen schicken Geodaten sind. Wir müssen also einen Query bauen, der uns alle Datensätze gibt, die “^http://daten-hamburg.de/” in der resources.url haben.
Mit http://wiki.apache.org/solr/CommonQueryParameters kann man komplexe Queries schreiben, sagt http://docs.ckan.org/en/latest/api/index.html#ckan.logic.action.get.package_search . Mit ein bisschen Scrollen stößt man gegebenenfalls auf resource_search und über Google nach “ckan resource_search” auf https://github.com/ckan/ckan/issues/1494, dessen Query man dann nimmt und sich damit nach http://suche.transparenz.hamburg.de/api/action/resource_search?query=url:http://daten-hamburg.de/ durchhangelt. Voll einfach! … Der Query dauert mehrere Sekunden und scheint ALLE Hits zurückzugeben, super!
Insgesamt sind es rund 104 Gigabyte, allerdings inklusive einiger Duplikate. Übrigens stecken auch SHA256-Hashes in den Daten, praktisch zum Überprüfen der Downloads.
The coordinates are wrong, I should have be xmin and ymin to match the official grid. Will update the PDFs soonish, sorry!
The LGV offers their official UTM grid for Hamburg in the Transparenzportal. Since many datasets are indexed by those grid tiles, it can be handy to have a quick references. Queue QGIS!
Load the layers “utm_raster1km any” and “utm_raster2km any” of the GML file. The CRS is EPSG:25832. Set their styles to have no fill.
Label with substr(x_min($geometry),0,4) || '\n' || substr(y_min($geometry),0,5) to truncate the coordinate display to just the interesting bits, the three leading numbers of X and the four leading numbers of Y.
Print them. You now have nice maps of the grid that you can use as reference when browsing through files with names like dgm1_32552_5936_2_fhh.xyz, LoD1_571_5939_1_HH.xml or dop20c_32576_5953.jpg (ignore the leading 32…).
I added the Stadtteile as background (and Wished QGIS could style by the 4 color theorem).
Click to download PDFs (they should be DIN A4, ask the composer why they are not):
Auf den großartigen Seiten des Hamburger Luftmessnetz kann man schöne Diagramme der verschiedenen Messwerte sehen, zum Beispiel von Feinstaub: PM10 oder PM2,5. Leider kann man nicht auf Diagramme sämtlicher Stationen verlinken, stattdessen muss der Benutzer sie per Hand zusammenstellen. Weil ich die Kurven gerne auf /r/dataisbeautiful verlinken wollte und die neuen Regeln dort etwas eigen sind, habe ich die Diagramme einfach mal mit Gnumeric nachgebaut.
Erstmal die Teilchen mit einem aerodynamischen Durchmesser von weniger als 10 Mikrometer (10 µm), PM10. Hiervon darf 35 mal Im Jahr ein Tagesmittelwert von 50µg/m³ überschritten werden.
Und dann noch die fieseren PM2,5 (kleiner 2,5µm), diese werden nur an drei Stationen gemessen:
In Berlin gibt es diese Werte leider nur täglich, aber der Feinstaub-Monitor der Berliner Morgenpost ist einen Blick wert (auch wenn er leider 2014 zu Ende gegangen ist?).
English version: This image shows the amount of particulate matter with a diameter of 10 micrometres or less in the days before and during new year 2014/2015 in Hamburg, Germany. This image shows the amount of particulate matter with a diameter of 2.5 micrometres or less.
Auch bundesweit gibt es schöne Werte, leider nur täglich. Das Umweltbundesamt stellt interpolierte Karten bereit, ich hab die letzten vier Tage mal zusammengefasst:
Schade, dass die Farbskala ein fixes Maximum hat, die Werte lagen ja wohl eher über 50µg/m³.
Dateien sollten sinnvoll benannt werden. Kreuzungsskizzen.zip mag im originalen Kontext funktionieren, aber ohne Datum, Herkunft oder Readme ist das Archiv für sich nicht sehr offensichtlich. Dass die Dateien darin dann zum Beispiel Poldata_poly.gml heißen, hilft dem Unkundigen nicht wirklich weiter. Mithilfe von Namespaces, zum Beispiel der veröffentlichenden Stelle, dem Datum usw wären lesbare, informative Dateinamen möglich.
Jede heruntergeladene Datei sollte auf irgendeine Weise Informationen über ihre Herkunft und Lizenz beinhalten. Bei Archiven wäre dies einfach über eine Textdatei mit demselben Namen möglich. Am besten auch noch gleich die Herkunfts-URL(s) mit rein. Ja, auch CSV-Dateien können mehr als Daten enthalten, einfach ein paar Headerzeilen rein und fertig.
Mehr Daten, weniger PDFs bitte. Du könntest doch bestimmt auch viel besser arbeiten, wenn alle Kinder ihre Wunschzettel standardisiert als Textdateien oder schönen strukturierten, freien Formaten einreichen würden oder?
Weniger Javascript, mehr Performanz für das Transparenzportal.
Mehr Homogenität in den Metadaten. Baugenehmigungen haben schöne beschreibende Titel, öffentliche Beschlüsse dagegen sind “total langweilige Nummern”.
Sortierung nach dem Datum der Daten, nicht nur der Veröffentlichung.
Eine schöne Einführung in die API, mit vielen Beispielen und Codeschnipseln.
Volltextsuche in allen Dokumenten, nicht nur den Metadaten im Portal. Ja, das wäre wirklich schön…
Redundanz! Die Downloads sollten redundant (und performant) vorgehalten werden, es nervt etwas, wenn man 10 Gigabyte Luftbilder mit 500 Kilobytes/s herunterladen muss oder wegen Wartungsarbeiten nicht an die Daten kommt.
Jeder Eintrag sollte einen direkten Link zum Download haben.
Jede Datei sollte mit einem Hash veröffentlicht werden (SHA1 oder SHA256 oder sowas). Änderungen von Daten müssen offensichtlich gemacht und dokumentiert werden. Daten dürfen nicht “heimlich” geändert werden, auch wenn es nur der erneute Upload eines defekten Archivs ist.
Und sag mir doch bitte unter welcher Lizenz die Texte und Grafiken im Transparenzportal selbst verfügbar sind?
Wie auch immer, ich danke dir für die vielen Stunden, die ich mit deinen Datengaben dieses Jahr schon spielen konnte. Schenkst du uns nächstes Jahr die Verpflichtung der Anstalten öffentlichen Rechts zur Veröffentlichung? Die drücken sich im Moment noch. Und sag bitte dem Bundestransparenzmenschen, dass die MTS-K-Daten doch nun wirklich einfach freigegeben werden sollten. Das wäre auch für die dortigen Mitarbeiter eine enorme Arbeitsentlastung.

























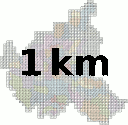




{kind=link}
{kind=link}