Die HomepageJeder Eintrag im Transparenzportal Hamburg wurde gespieltMan konnte Suchen speichern und bei neuen Ergebnissen eine Mail erhalten
Ein Beispiel für einen EintragEin Eintrag mit mehreren verknüpften Resourcen
Die Idee war ursprünglich, dass dort Kommentare und Diskussionen zu den im Transparenzportal Hamburg (TPHH) veröffentlichten Datensätzen gepostet werden könnten. Und das vielleicht sogar direkt im TPHH eingebettet.
Dazu hat ein Python-Skript (als Bot namens “Heidi Kabel” ;) ) jede Minute die API des TPHH nach neuen Datensätzen gefragt, die Metadaten abgerufen und sie schön formatiert und aufbereitet als Foren-Threads gepostet. Ein spaßiges Bastel-Projekt, irgendwann 2019.
Die Dokumentation für die Forumsinstallation und der Code für den Bot liegen in:
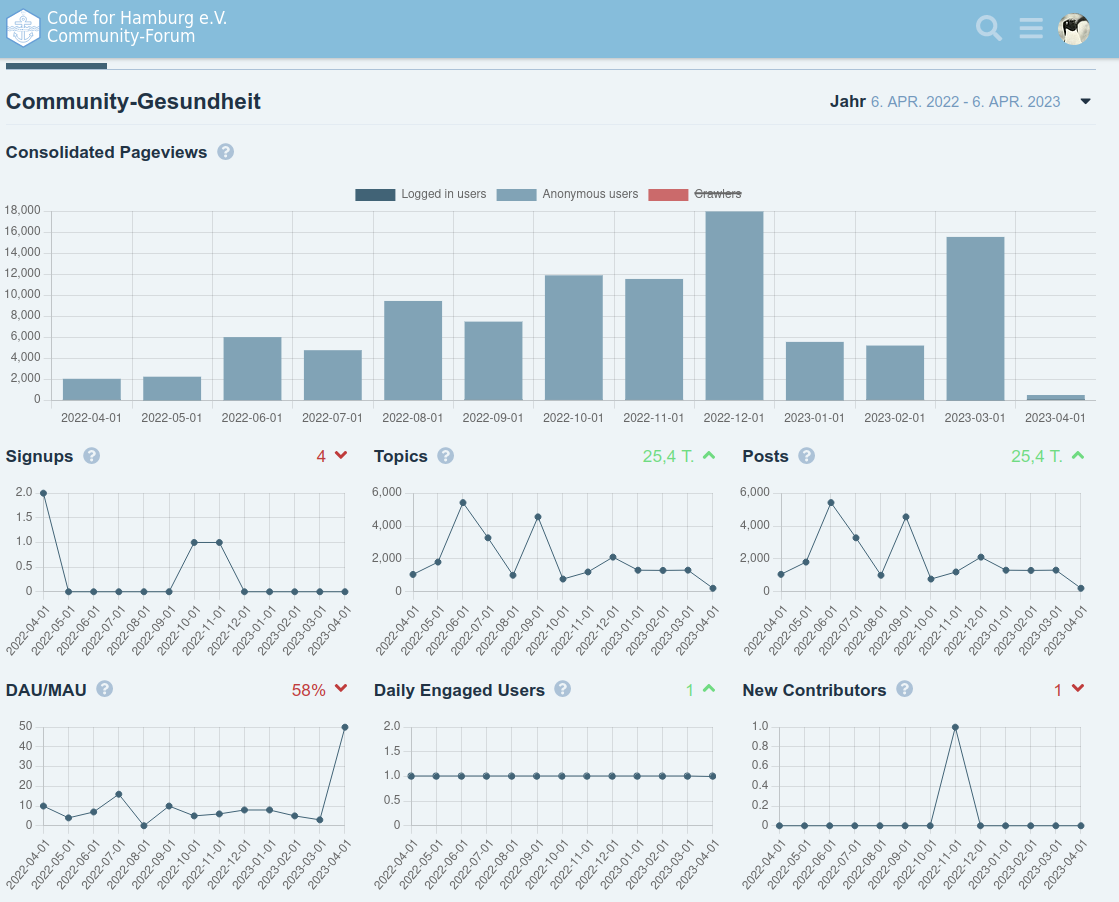
Naja, dann kam Corona und Treffen von Code for Hamburg gab’s eh schon kaum noch. Die Seite hat praktisch niemand außer mir genutzt, es gab keine 10 Posts, die nicht vom Bot waren. Mit der Einbindung im TPHH wurde es auch nichts (ich hatte mich aber auch nicht drum gekümmert).
“Angesagte” Posts mit vielen Views
Pageviews exklusive (erkannte) CrawlerTop Referred Topics (keine Ahnung wo sie verlinkt wurden)
Der tägliche User war unser TPHH-Spiegel-Bot, die Posts/Topics auch
Ich hatte es für mich selbst noch als einfaches Interface für die Daten und als praktischen Benachrichtigungsservice auf bestimmte Keywords genutzt, aber jetzt klappt das Update der Forensoftware nicht mehr (Bug von Discourse mit angeblich nicht mehr einzigartigen Tags und es gab keine Rückmeldung auf meine Fragen, von daher …) und ich will da nix auf veralteter Software laufen lassen. Übernehmen wollte es niemand aus dem Verein und im Fediverse hat sich auch niemand gemeldet. Von daher mach ich die Tage das Licht aus.
PS: Ich hoffe Code for Hamburg wird irgendwann mal wieder reaktiviert, mit regelmäßigen Treffen, wo gehackt und gebastelt wird. Toi toi toi!
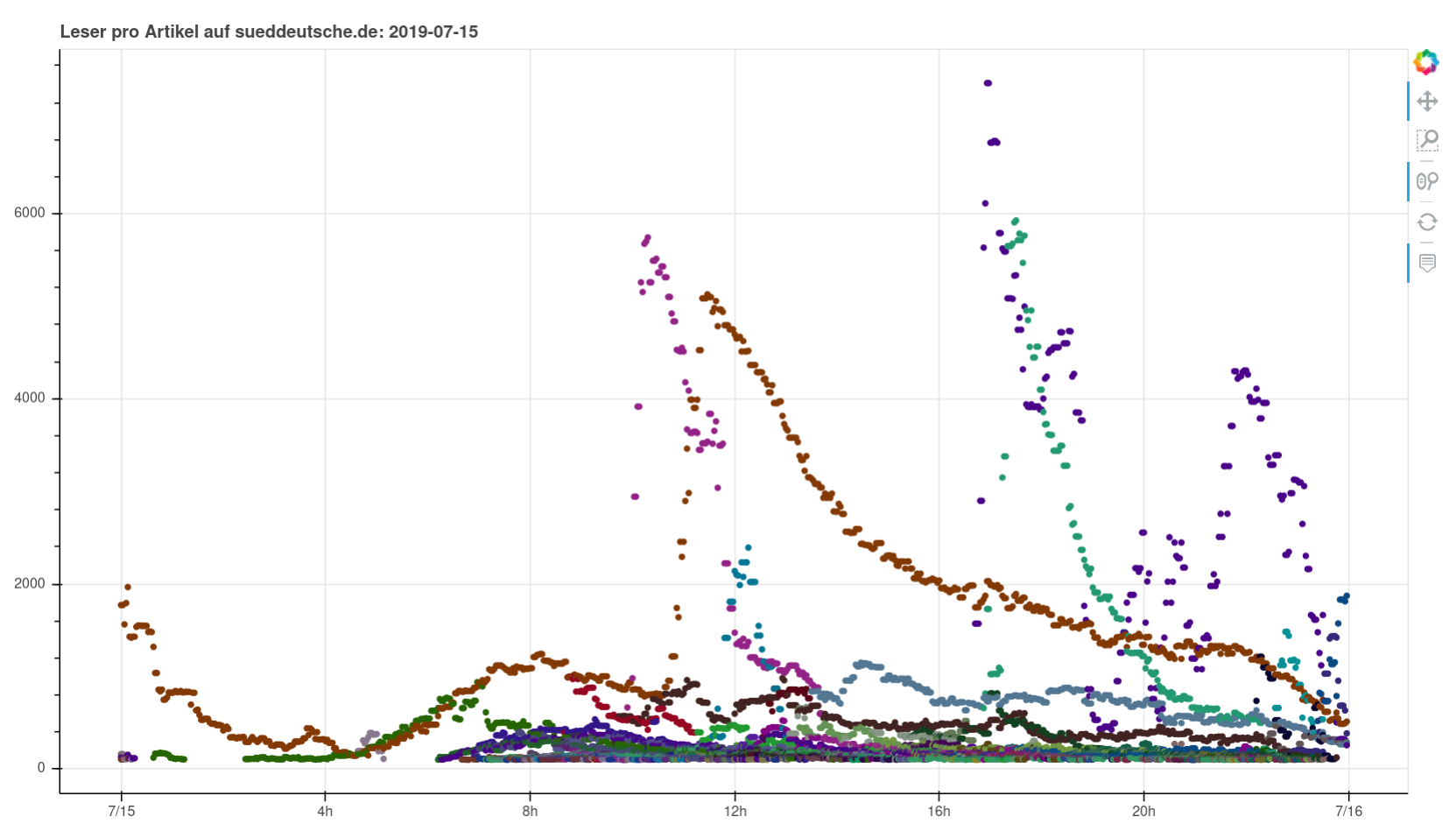
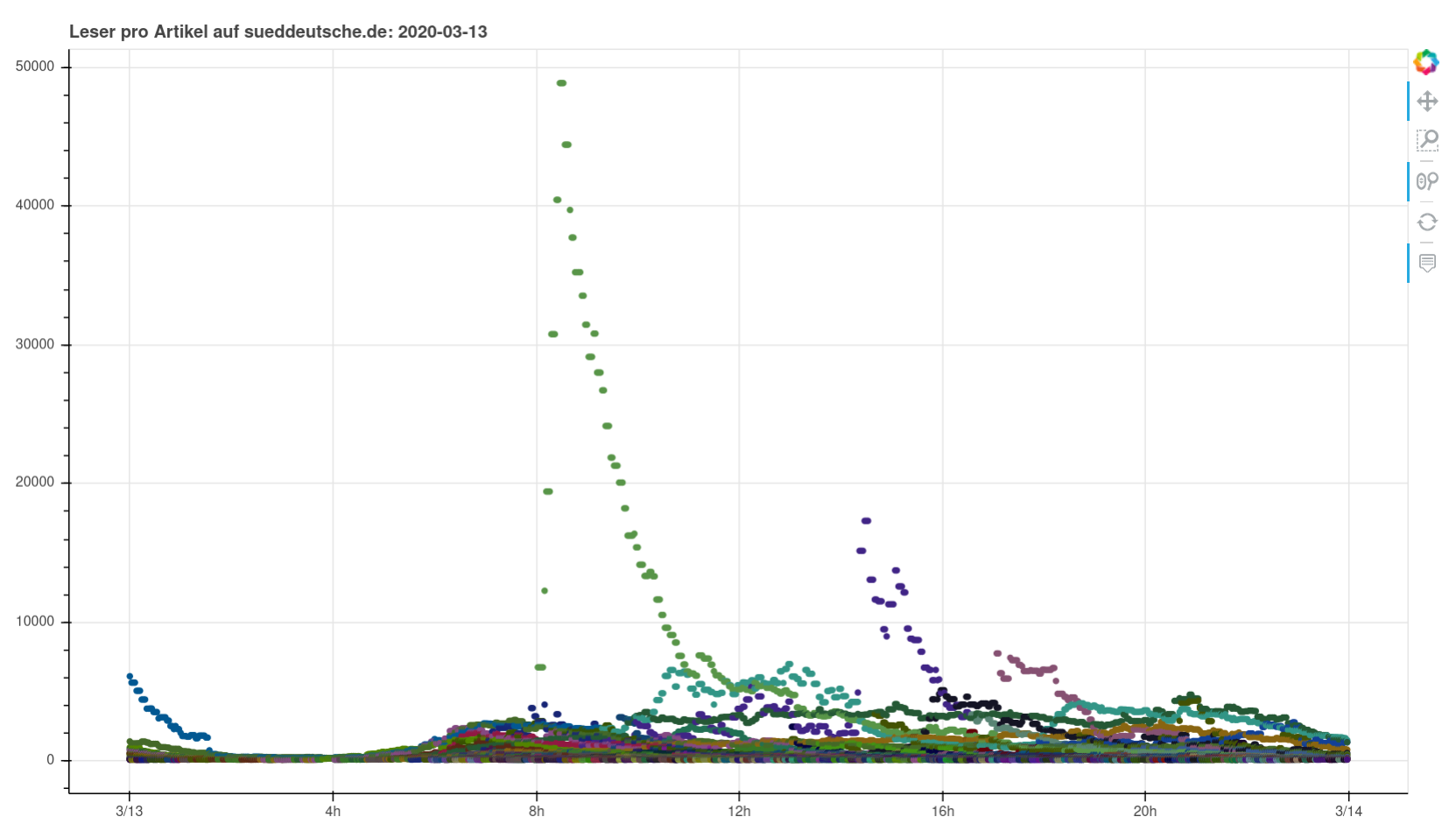
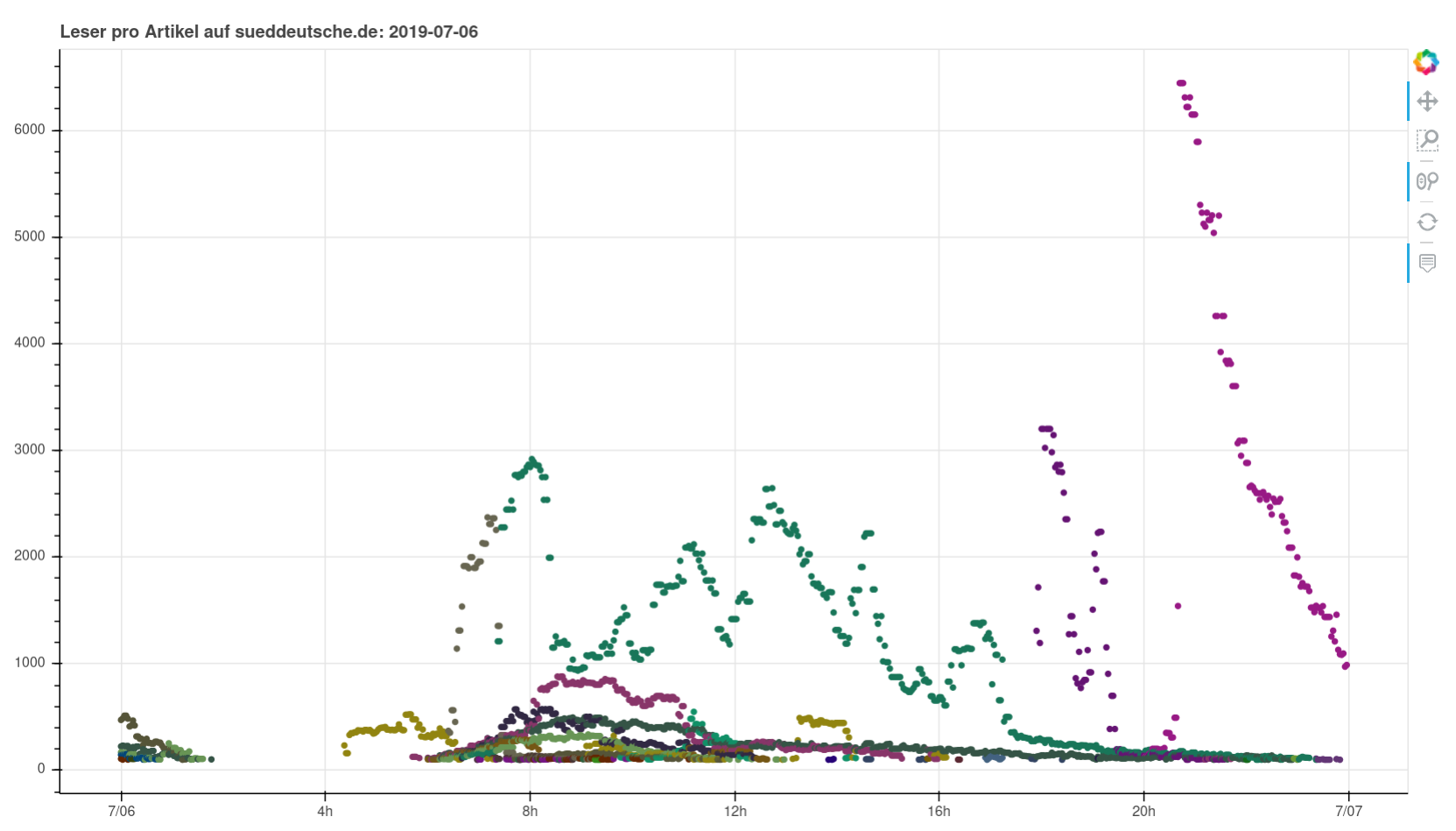
I scraped the numbers of live readers per article published by Süddeutsche Zeitung on their website for more than 3 years, never did anything too interesting with it and just decided to stop. Basically they publish a list of stories and their estimated current concurrent number of readers. Meaning you get a timestamp -> story/URL -> number of current readers. Easy enough and interesting for sure.
Here is how it worked, some results and data for you to build upon. Loads of it is stupid and silly, this is just me dumping it publicly so I can purge it.
Database
For data storage I chose the dumbest and easiest approach because I did not care about efficiency. This was a bit troublesome later when the VPS ran out of space but … shrug … I cleaned up and resumed without changes. Usually it’s ok to be lazy. :)
So yeah, data storage: A SQLite database with two tables:
Can you spot the horrible bloating issue? Yeah, when the (same) URLs are stored again and again for each row, that gets big very quickly. Well, I was too lazy to write something smarter and more “relational”. Like this it is only marginally better than a CSV file (I used indexes on all the fields as I was playing around…). Hope you can relate. :o)
Scraping
#!/usr/bin/env python3
from datetime import datetime
from lxml import html
import requests
import sqlite3
import os
# # TODO
# - store URLs in a separate table and reference them by id, this will significantly reduce size of the db :o)
# - more complicated insertion queries though so ¯\\\_(ツ)\_/¯
# The site updates every 2 minutes, so a job should run every 2 minutes.
# # Create database if not exists
sql_initialise = """
CREATE TABLE visitors_per_url (timestamp TEXT, visitors INTEGER, url TEXT);
CREATE TABLE visitors_total (timestamp TEXT, visitors INTEGER);
CREATE INDEX idx_visitors_per_url_timestamp ON visitors_per_url(timestamp);
CREATE INDEX idx_visitors_per_url_url ON visitors_per_url(url);
CREATE INDEX idx_visitors_per_url_timestamp_url ON visitors_per_url(timestamp, url);
CREATE INDEX idx_visitors_total_timestamp ON visitors_total(timestamp);
CREATE INDEX idx_visitors_per_url_timestamp_date ON visitors_per_url(date(timestamp));
"""
if not os.path.isfile("sz.db"):
conn = sqlite3.connect('sz.db')
with conn:
c = conn.cursor()
c.executescript(sql_initialise)
conn.close()
# # Current time
# we don't know how long fetching the page will take nor do we
# need any kind of super accurate timestamps in the first place
# so let's truncate to full minutes
# WARNING: this *floors*, you might get visitor counts for stories
# that were released almost a minute later! timetravel wooooo!
now = datetime.now()
now = now.replace(second=0, microsecond=0)
print(now)
# # Get the webpage with the numbers
page = requests.get('https://www.sueddeutsche.de/news/activevisits')
tree = html.fromstring(page.content)
entries = tree.xpath('//div[@class="entrylist__entry"]')
# # Extract visitor counts and insert them to the database
# Nothing smart, fixed paths and indexes. If it fails, we will know the code needs updating to a new structure.
total_count = entries[0].xpath('span[@class="entrylist__count"]')[0].text
print(total_count)
visitors_per_url = []
for entry in entries[1:]:
count = entry.xpath('span[@class="entrylist__socialcount"]')[0].text
url = entry.xpath('div[@class="entrylist__content"]/a[@class="entrylist__link"]')[0].attrib['href']
url = url.replace("https://www.sueddeutsche.de", "") # save some bytes...
visitors_per_url.append((now, count, url))
conn = sqlite3.connect('sz.db')
with conn:
c = conn.cursor()
c.execute('INSERT INTO visitors_total VALUES (?,?)', (now, total_count))
c.executemany('INSERT INTO visitors_per_url VALUES (?,?,?)', visitors_per_url)
conn.close()
This ran every 2 minutes with a cronjob.
Plots
I plotted the data with bokeh, I think because it was easiest to get a color category per URL (… looking at my plotting script, ugh, I am not sure that was the reason).
#!/usr/bin/env python3
import os
import sqlite3
from shutil import copyfile
from datetime import datetime, date
from bokeh.plotting import figure, save, output_file
from bokeh.models import ColumnDataSource
# https://docs.python.org/3/library/sqlite3.html#sqlite3.Connection.row_factory
def dict_factory(cursor, row):
d = {}
for idx, col in enumerate(cursor.description):
d[col[0]] = row[idx]
return d
today = date.isoformat(datetime.now())
conn = sqlite3.connect('sz.db')
conn.row_factory = dict_factory
with conn:
c = conn.cursor()
c.execute(
"""
SELECT * FROM visitors_per_url
WHERE visitors > 100
AND date(timestamp) = date('now');
"""
)
## i am lazy so i group in sql, then parse from strings in python :o)
#c.execute('SELECT url, group_concat(timestamp) AS timestamps, group_concat(visitors) AS visitors FROM visitors_per_url GROUP BY url;')
visitors_per_url = c.fetchall()
conn.close()
# https://bokeh.pydata.org/en/latest/docs/user_guide/data.html so that the data is available for hover
data = {
"timestamps": [datetime.strptime(e["timestamp"], '%Y-%m-%d %H:%M:%S') for e in visitors_per_url],
"visitors": [e["visitors"] for e in visitors_per_url],
"urls": [e["url"] for e in visitors_per_url],
"colors": [f"#{str(hash(e['url']))[1:7]}" for e in visitors_per_url] # lol!
}
source = ColumnDataSource(data=data)
# https://bokeh.pydata.org/en/latest/docs/gallery/color_scatter.html
# https://bokeh.pydata.org/en/latest/docs/gallery/elements.html for hover
p = figure(
tools="hover,pan,wheel_zoom,box_zoom,reset",
active_scroll="wheel_zoom",
x_axis_type="datetime",
sizing_mode='stretch_both',
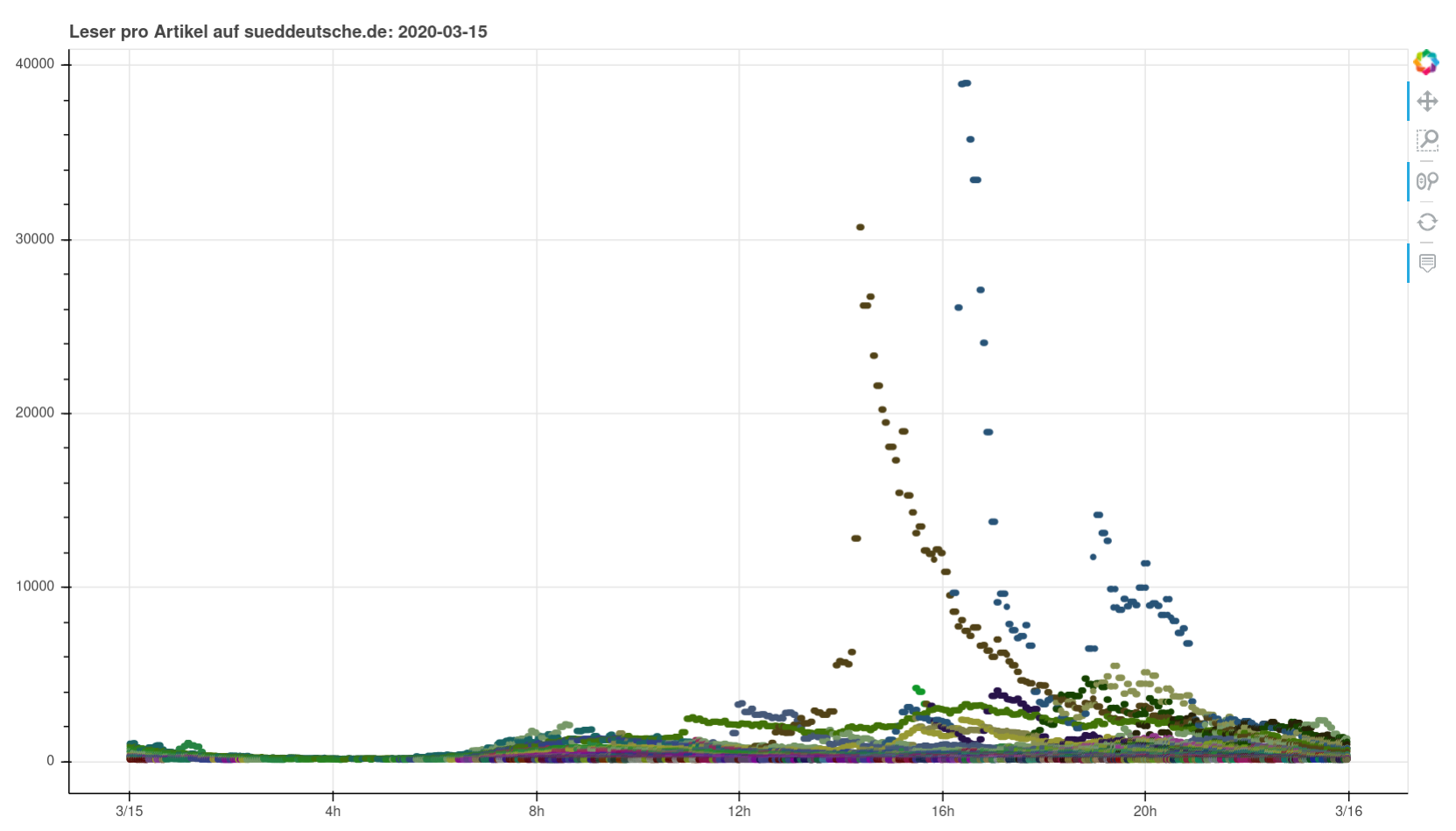
title=f"Leser pro Artikel auf sueddeutsche.de: {today}"
)
# radius must be huge because of unixtime values maybe?!
p.scatter(
x="timestamps", y="visitors", source=source,
size=5, fill_color="colors", fill_alpha=1, line_color=None,
#legend="urls",
)
# click_policy does not work, hides everything
#p.legend.location = "top_left"
#p.legend.click_policy="hide" # mute is broken too, nothing happens
p.hover.tooltips = [
("timestamp", "@timestamps"),
("visitors", "@visitors"),
("url", "@urls"),
]
output_file(f"public/plot_{today}.html", title=f"SZ-Leser {today}", mode='inline')
save(p)
os.remove("public/plot.html") # will fail once :o)
copyfile(f"public/plot_{today}.html", "public/plot.html")
Results and findings
Nothing particularly noteworthy comes to mind. You can see perfectly normal days, you can see a pandemic wrecking havoc, you can see fascists being fascists. I found it interesting to see how you can clearly see when articles were pushed on social media or put on the frontpage (or off).
https://suche.transparenz.hamburg.de.EXAMPLE.COM/api/action/resource_search?query=url: (“.EXAMPLE.COM” entfernen) liefert aktuell rund 200 Megabyte an JSON, da sollten alle Resourcen drin stecken oder zumindest die, die tatsächlich einen Datensatz referenzieren
Um es in normalen Editoren besser handlebar zu machen, hilft json_pp:
Egal. Das ist ja großartig! Da werden eine Menge von Anwendungen ermöglicht (Sichtachsen! Verschattungen! Vermaschung! VR! AR!) und verschiedenste Akteure werden die Daten absolut feiern. Auch wenn es mit 1 Meter Auflösung wirklich mies grob ist, auf ein 1 Meter Gitter gerastert ist (nicht ausgedünnt, d. h. es ist teilweise stärker verfälscht und “daneben”) und “nur” bildbasiert (nicht gescannt) ist, geht da schon einiges mit.
Ausprobieren! Im Browser!
Achtung, frickelige Bedienung! Am besten den WASD-Möwen-Modus nutzen, mit Speed 1000. Oder mit einem Doppelklick irgendwo hinzoomen.
Für 2018 liegen die Daten als 12768 einzelne XYZ-Kacheln vor, also als super ineffiziente Textdateien. Insgesamt sind es rund 22 Gigabyte. Für 2020 sind es stattdessen 827 größere Kacheln, aber ebenfalls in XYZ mit einem ähnlichem Platzbedarf.
Schönerweise gibt es freie Tools wie LAStools‘ txt2las, was sie schnell und einfach ins super effiziente LAZ-Format umwandeln kann:
und 4 Minuten später ist die interaktive 3D-Webanwendung fertig, wegen der zusätzlichen Octree-Struktur jetzt bei rund 3 Gigabyte.
Punktwolke mit Farben aus Orthophoto einfärben
Die bereitgestellten Oberflächenmodelle sind so schlicht wie es nur geht, es sind reine XYZ-Daten ohne weitere Dimensionen wie Farbe o. ä.
Glücklicherweise gibt es ja auch die Orthophotos, eventuell wurde sogar dasselbe Bildmaterial genutzt? Da müsste mal jemand durch den Datenwust wühlen, die bei den DOPs werden die relevanten Metadaten nicht mitgeliefert…
Theoretisch könnte man sie also einfärben. Leider ist lascolor proprietär und kommt mit gruseligen, bösartigen Optionen, wenn man es wagt es “unlizenziert” zu nutzen (“Please note that the unlicensed version will (…) slightly change the LAS point order, and randomly add a tiny bit of white noise to the points coordinates once you exceed a certain number of points in the input file.”) und kann JPEG in GeoTIFF nicht lesen (so hab ich mir die DOPs aufbereitet). Eine Alternative ist das geniale PDAL. Mit einer Pipeline wie
ist die Punktwolke innerhalb von Minuten coloriert und kann dann wie gehabt mit PotreeConverter in einen interaktiven 3D-Viewer gesteckt werden.
Update 2023: "minor_version": "2" -> "minor_version": "4", damit LAS 1.4 rauskommt, um dann einfach COPC draus bauen zu können (Farben als 16-Bit, nicht 8-Bit). Und entsprechend noch ein Filter, um die Farben auf den 16-Bit-Wertebereich zu skalieren, das passiert leider nicht automatisch.
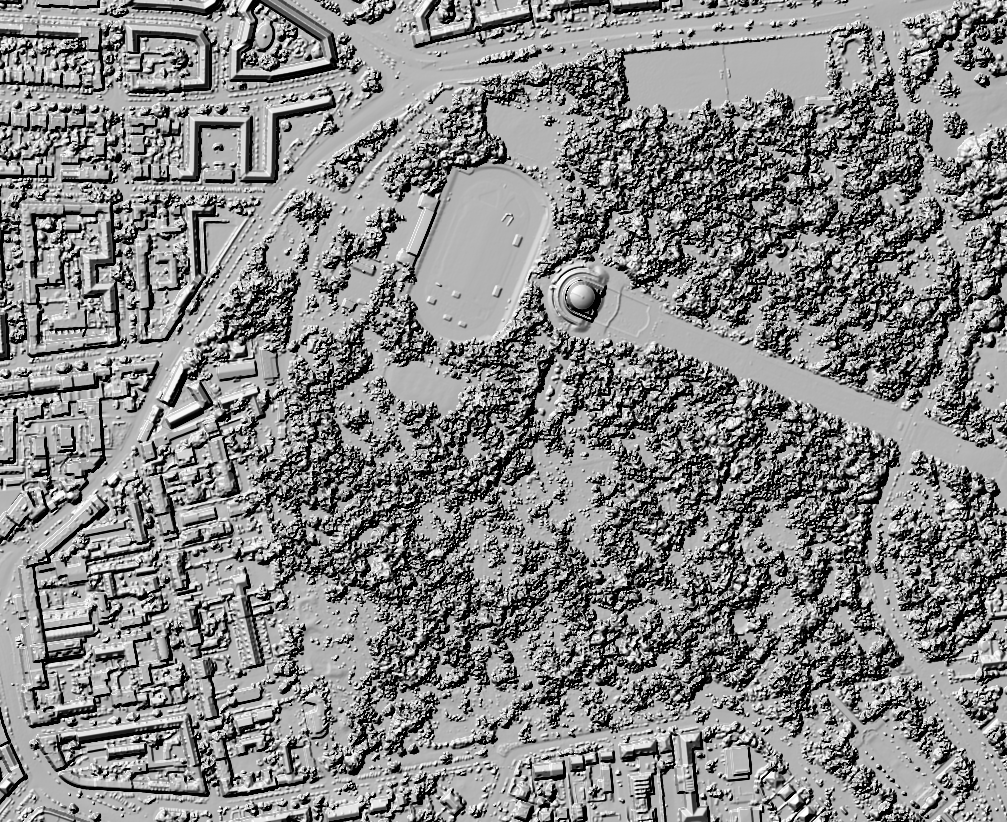
Das Ergebnis ist besser als erwartet, da es scheinbar tatsächlich die selben Bilddaten sind (für beide Jahre). Andererseits ist es auch nicht wirklich schick, da die DOPs nicht als True Orthophoto vorliegen und damit höhere Gebäude gekippt in den Bilder abgebildet sind. Sieht man hier schön am Planetarium.
Cloud-Optimized Point Cloud
Als Cloud-Optimized Point Cloud umwandeln kann man das Resultat einfach mit untwine (mit pdal pipeline braucht man immens viel RAM (>64GB), da die Umwandlung nach COPC hier nicht den Streaming Mode nutzen kann):
Anschließend auf einem Server (mit entsprechenden Access-Control-Allow-Headern) gelagert, kann die Punktwolke super einfach mit https://viewer.copc.io/?resources=https://example.com/pointcloud.copc.laz im Browser verwendet werden. Ganz ohne Umwandlung in viele Unterdateien wie beim PotreeConverter.
DOM als GeoTIFF
Wer es lieber als GeoTIFF haben möchte, hat es etwas schwerer, denn GDAL kommt mit dieser Art von Kacheln (mit Lücken und in der bereitgestellten Sortierung) nicht gut klar. Mein Goto-Tool dafür ist GMT.
Hier mal im Vergleich mit dem DGM1 als Schummerungen:
Vermaschung als 3D-Modell
Leider habe ich keine gute Lösung für die 3D-Vermaschung gefunden. tin-terrain und dem2mesh kommen nicht mit so großen Datenmengen auf einmal klar und weiter hab ich nicht geschaut. Wer da was gutes weiß kann sich bei mir bei nächster Gelegenheit Kekse oder Bier abholen. ;)
Daten hinter den Bildern und den Viewern Datenlizenz Deutschland Namensnennung 2.0, Freie und Hansestadt Hamburg, Landesbetrieb Geoinformation und Vermessung (LGV)
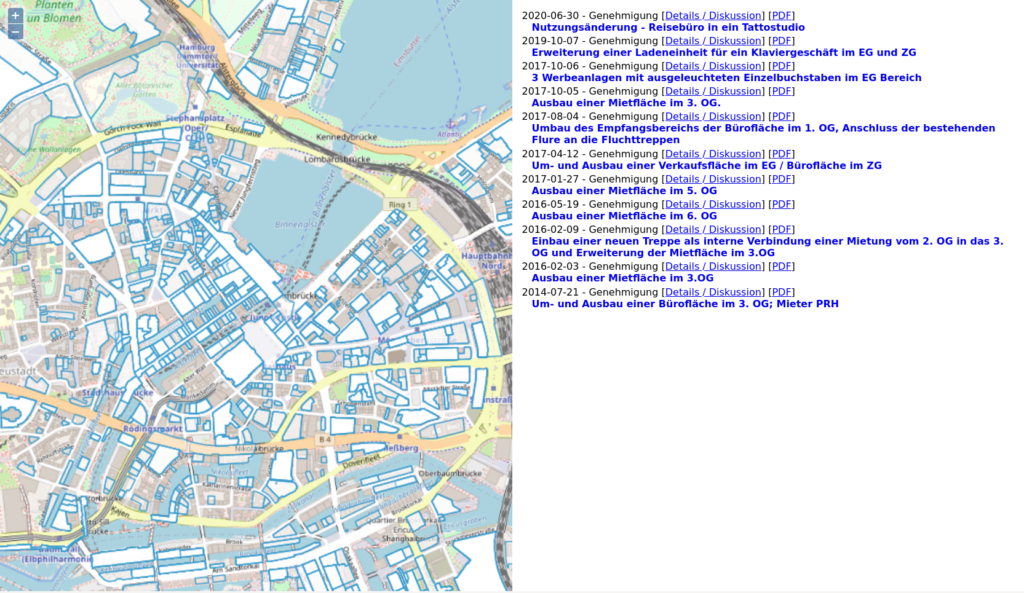
Je weniger transparent eine Fläche dargestellt ist, desto mehr Dokumente sind mit ihr verknüpft (ja, es ist ein Feature je Dokument D;). Eigentlich war die Seite anders aufgebaut, mit einem PDF-Viewer auf der rechten Seite. Aber da daten.transparenz.hamburg.de kein HTTPS kann (seid ihr auch so gespannt auf die UMTS-Auktion nächste Woche?), geht das aus Sicherheitsgründen nicht ohne ein Spiegeln der Daten oder einen Proxy.
Die Daten kommen größtenteils aus dem Transparenzportal. Für das Matching der angebenen Flurstücks-“IDs” zu den tatsächlichen Flurstücken war aber ein erheblicher Aufwand nötig. Das Drama ging bis hin zum Parsen aus PDFs, die mal so, mal so formatiert waren und natürlich auch voller Eingabefehler auf Behördenseite. Vielleicht schreibe ich da noch beizeiten mal einen Rant. TL;DR: Ohne die zugehörige Gemarkung ist mit einer Flurstücks-“ID” wie in den Daten angegeben keine räumliche Zuordnung möglich. In den veröffentlichten Daten stecken nur die Nenner der Flurstücksnummern, nicht aber die Gemarkungsnummern. Ziemlich absurd.
Das ganze ist nur ein Prototyp, vermutlich voller Fehler und fehlender Daten. Aber interessant und spaßig ist es, viel Freude also!
Es wäre noch eine MENGE zu tun, um das ganze rund zu machen. Falls du Lust hast, melde dich gerne. Es geht vom wilden Parsen, über Sonderregeln für kaputte Dokumente, zu Kartenstyling bis zur UI. Schön wäre es auch alles in einer anständigen Datenbank zu halten und nicht nur nach der räumlichen Dimension durchsuchen zu können.
Mediatheken des Öffentlich-rechtlichen Rundfunks müssen wegen asozialen Arschlöchern ihre Inhalte depublizieren. Wegen anderer Arschlöcher sind die Inhalte nicht konsequent unter freien Lizenzen, aber das ist ein anderes Thema.
Ich hatte mir irgendwann mal angesehen, was es eigentlich für ein Aufwand wäre, die Inhalte verschiedener Mediatheken in ein privates Archiv zu spiegeln. Mit dem Deutschlandradio hatte ich angefangen und mit den üblichen Tools täglich die neuen Audiobeiträge in ein Google Drive geschoben. Dieses Setup läuft jetzt seit mehr als 2 Jahren ohne Probleme und vielleicht hat ja auch wer anders Spaß dran:
Also:
rclone einrichten oder mit eigener Infrastruktur arbeiten (dann die rclone-Zeile mit z.B. rsync ersetzen)
<20 GB Platz haben
Untenstehendes Skript als täglichen Cronjob einrichten (und sich den Output zu mailen lassen)
#!/bin/bash
# exit if anything fails
# not a good idea as downloads might 404 :D
set -e
cd /home/dradio/deutschlandradio
# get all available files
wget -nv -nc -x "http://srv.deutschlandradio.de/aodlistaudio.1706.de.rpc?drau:page="{0..100}"&drau:limit=1000"
grep -hEo 'http.*mp3' srv.deutschlandradio.de/* | sort | uniq > urls
# check which ones are new according to the list of done files
comm -13 urls_done urls > todo
numberofnewfiles=$(wc -l todo | awk '{print $1}')
echo "${numberofnewfiles} new files"
if (( numberofnewfiles < 1 )); then
echo "exiting"
exit
fi
# get the new ones
echo "getting new ones"
wget -i todo -nv -x -nc || echo "true so that set -e does not exit here :)"
echo "new ones downloaded"
# copy them to remote storage
rclone copy /home/dradio_scraper/deutschlandradio remote:deutschlandradio && echo "rclone done"
## clean up
# remove files
echo "cleaning up"
rm -r srv.deutschlandradio.de/
rm -rv ondemand-mp3.dradio.de/
rm urls
# update list of done files
cat urls_done todo | sort | uniq > /tmp/urls_done
mv /tmp/urls_done urls_done
# save todo of today
mv todo urls_$(date +%Y%m%d)
echo "done"
Pro Tag sind es so 2-3 Gigabyte neuer Beiträge.
In zwei Jahren sind rund 2,5 Terabyte zusammengekommen und ~300.000 Dateien, aber da sind eventuell auch die Seiten des Feeds mitgezählt worden und Beiträge, die schon älter waren.
Wer mehr will nimmt am besten direkt die Mediathekview-Datenbank als Grundlage.
Nächster Schritt wäre das eigentlich auch täglich nach archive.org zu schieben.
Die FOSSGIS 2017 in Passau war grandios. Ich bin sooo froh, dass ich mich auf den weiten Weg gemacht hatte. Die Liste von Vortragsaufzeichnungen, die ich selbst noch anschauen will, ist lang… Ausprobieren muss ich unbedingt (mal wieder) ein aktuelles GRASS GIS, GVSIG CE (das Poster hat Lust gemacht), osmium, die ganzen Vector Tiles Tools uvm.
Der LT kam so extrem gut an, dass ich nächstes Mal wohl um einen richtigen Vortrag oder auch Workshop kaum herum komme. :o)
Für den Geopackage-Vortrag hatte ich leider die Daten und Skripte zuhause gelassen und musste daher etwas improvisieren… Trotzdem war kam auch er gut an und ich habe großartigen Input bekommen, z.B. dass es ein tolles neues QGIS-Plugin für GML Application Schema Gedöns gibt und einen GMLAS-Treiber in GDAL. Danke!
Bei spontanen QGIS-Anwender- und Vereinstreff habe ich nachgefragt, wie es eigentlich mit QGIS an den Hochschulen aussieht und wie ich meinen Arbeitgeber vielleicht mal auf den Weg von Esri/IDRISI zu QGIS bringen kann. Da war ausser Claas Leiners Lehre in Kassel wenig bekannt. Vielleicht starte ich mal eine kleine Recherche, um etwas Einblick in die Landschaft zu bekommen. Wäre doch klasse, wenn sich mehr Unis von proprietärer Software entsagen mögen!
Let’s take it to the next level: Wir wollen alle auf daten-hamburg.de gehosteten Datensätze, weil da die ganzen schicken Geodaten sind. Wir müssen also einen Query bauen, der uns alle Datensätze gibt, die “^http://daten-hamburg.de/” in der resources.url haben.
Mit http://wiki.apache.org/solr/CommonQueryParameters kann man komplexe Queries schreiben, sagt http://docs.ckan.org/en/latest/api/index.html#ckan.logic.action.get.package_search . Mit ein bisschen Scrollen stößt man gegebenenfalls auf resource_search und über Google nach “ckan resource_search” auf https://github.com/ckan/ckan/issues/1494, dessen Query man dann nimmt und sich damit nach http://suche.transparenz.hamburg.de/api/action/resource_search?query=url:http://daten-hamburg.de/ durchhangelt. Voll einfach! … Der Query dauert mehrere Sekunden und scheint ALLE Hits zurückzugeben, super!
Insgesamt sind es rund 104 Gigabyte, allerdings inklusive einiger Duplikate. Übrigens stecken auch SHA256-Hashes in den Daten, praktisch zum Überprüfen der Downloads.