TanDEM-X promo images in their full resolution at the bottom, SRTMGL1 at maximum resolution at the top.

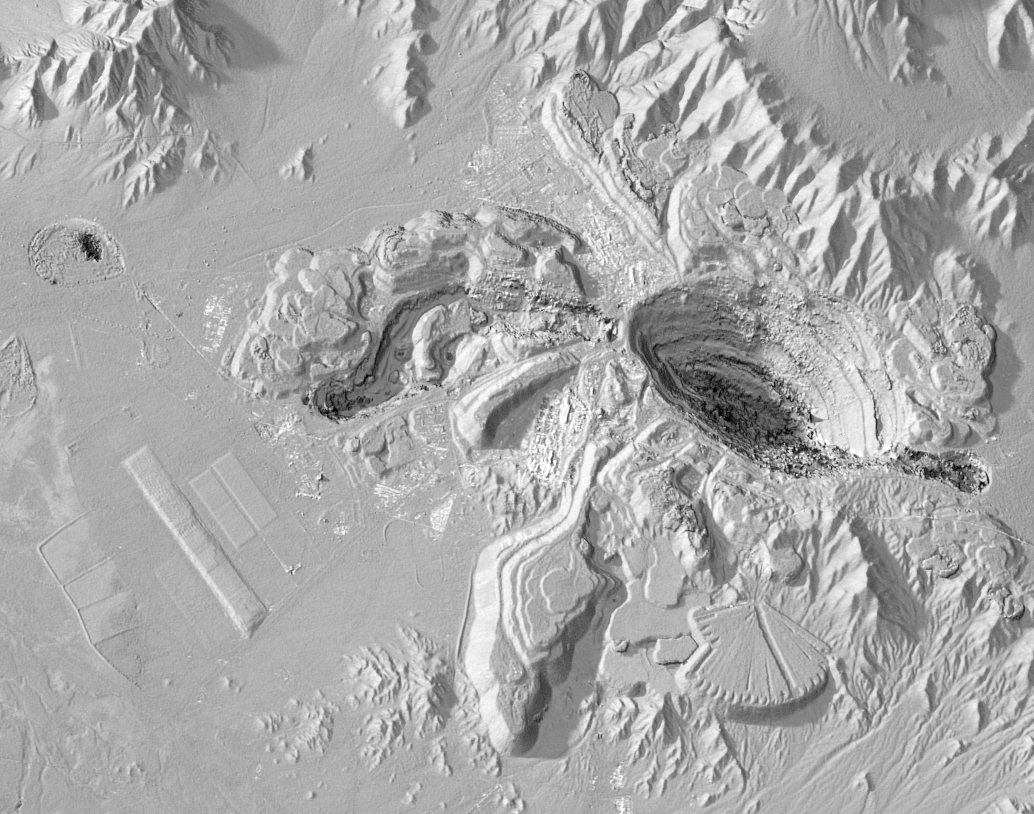
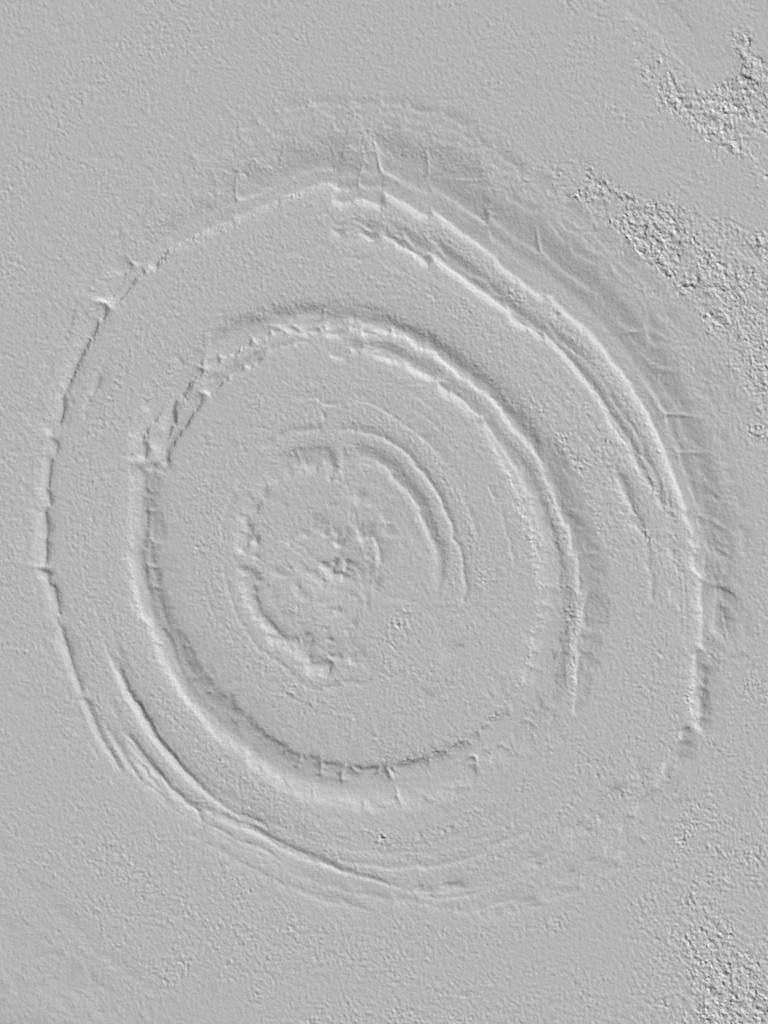
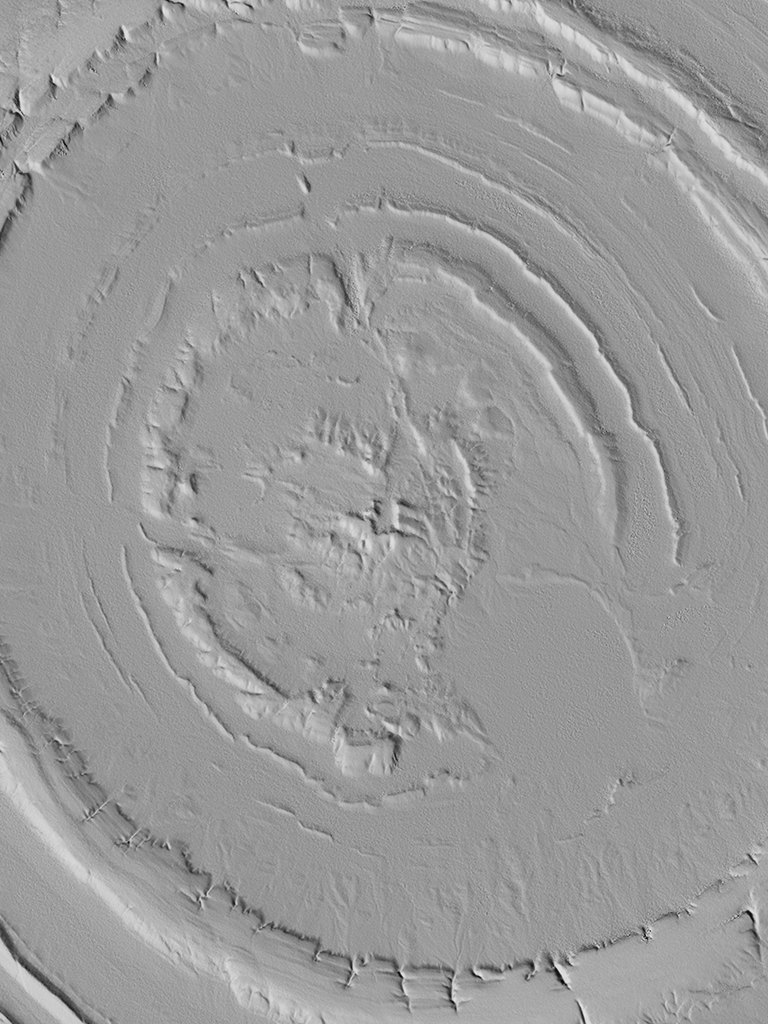
If only TanDEM-X data was freely available instead of incredibly expensive.
TanDEM-X promo images in their full resolution at the bottom, SRTMGL1 at maximum resolution at the top.
If only TanDEM-X data was freely available instead of incredibly expensive.
Following Doing things to the whole map canvas in QGIS and adding some blending to the mix (he-he), I ended up with this map. Nothing you could not do with simple post-processing in a raster image editor or even QGIS’ map composer I guess.

It was simply the result of playing around, there probably is a faster or more efficient way.
First give your geometries some fancy texture with Raster image fill (left). Then constrict its display to just some blurry borders by using a grey fill, Blur draw effect with maximum strength and the Dodge Layer blending mode (right).


You could probably skip the texture for the geometry but I did not manage to get a similarly nice effect with a Simple fill.
Use the trick from Doing things to the whole map canvas in QGIS to fill your canvas with a polygon and give that a nice texture as well. Use Multiply as Layer blending mode and get social media hype for that unbelievable stain can you believe it looks like that???
From the same session comes this beauty (mostly due to Tom Patterson’s shading of course ;) ):
Due to a minor bug in QGIS you need a very recent testing build. 2.16.3 is not recent enough but 2.16.4 would be.
For cool tricks like vignetting or other eye candy, having a geometry that spans the whole map canvas in QGIS can be very useful.
Using the @map_* Variables available in expressions in combination with a Geometry generator style allows you to do this.
@map_extent_center returns a Point geometry of the current map canvas center, with x(@map_extent_center) and y(@map_extent_center) you get the x and y coordinates of it in the current CRS.
@map_extent_width and @map_extent_height return the width respectively height of the map canvas in CRS units.
Our goal is to create a polygon that exactly matches the map canvas extents. Some simple math gets you there.
First create Points for each of the corners by alternating the x+/-width and y+/-height. Then create a Line from all of them (the last point does not need to be the first again, make_polygon does that for you). And use the line as outer ring for a Polygon.
make_polygon( make_line( make_point(x(@map_extent_center)-@map_extent_width/2, y(@map_extent_center)-@map_extent_height/2), make_point(x(@map_extent_center)+@map_extent_width/2, y(@map_extent_center)-@map_extent_height/2), make_point(x(@map_extent_center)+@map_extent_width/2, y(@map_extent_center)+@map_extent_height/2), make_point(x(@map_extent_center)-@map_extent_width/2, y(@map_extent_center)+@map_extent_height/2) ) ) |
To actually see this, you need to use the style on a layer with at least one feature that is always visible where you want to focus your map canvas. Just make a polygon layer with one polygon that encloses the whole area. The layer must be in the same CRS as the project I think.
You now have a Polygon that corresponds with the map canvas. Give it a radial gradient fill with some transparency and party!





All aerial images in the examples are
Lizenz: Datenlizenz Deutschland Namensnennung 2.0
Namensnennung: Freie und Hansestadt Hamburg, Landesbetrieb Geoinformation und Vermessung
http://daten-hamburg.de/geographie_geologie_geobasisdaten/digitale_orthophotos/DOP20/DOP20_HH_fruehjahrsbefliegung_2015.zip
To make sure the feature you want to highlight is in the center, you could use another layer and @map_extent_center.
Yes, this totally is a hack but it’s fun!
Wrote this in 2014, not sure why I did not publish it. It was a response to this bad map.
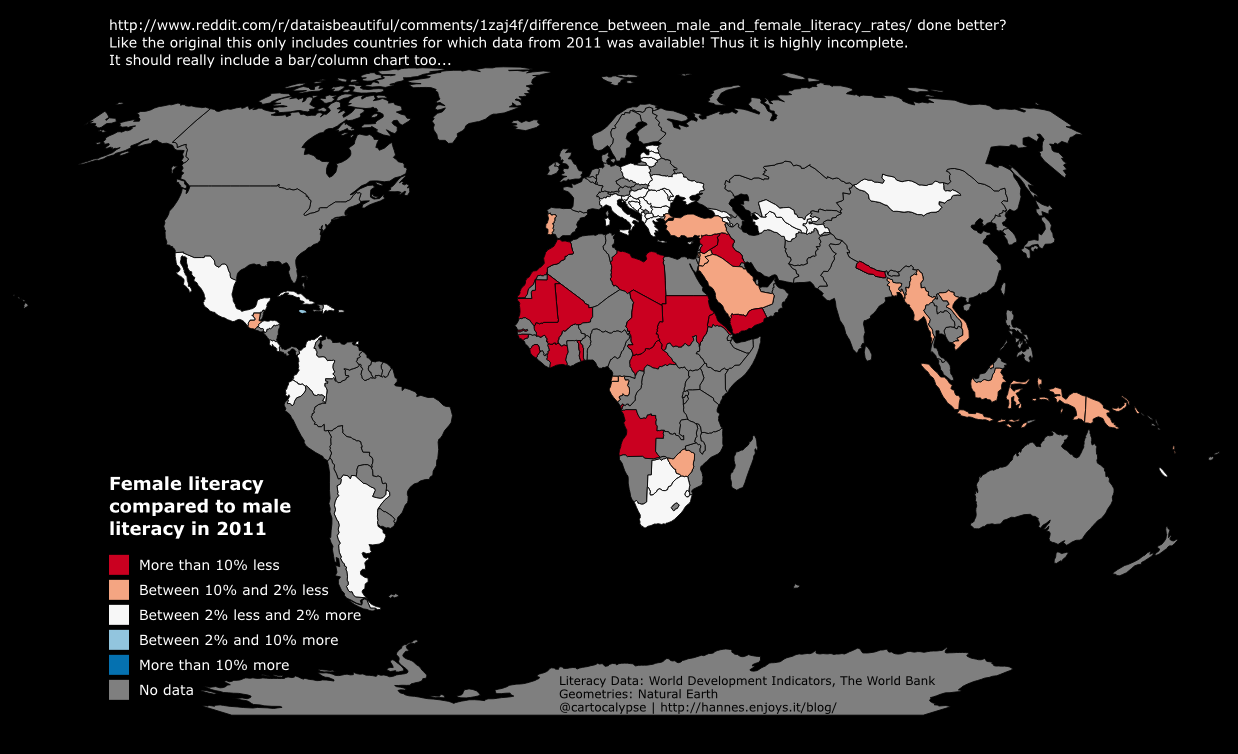
No need for expensive software, you can use the free and open-source QGIS for this: https://qgis.org/
1. Install QGIS
2. Download and unzip the data http://databank.worldbank.org/data/download/WDI_excel.zip (not sure what license, they want attribution “World Development Indicators, The World Bank”)
3. Download and unzip country geometries http://www.naturalearthdata.com/http//www.naturalearthdata.com/download/50m/cultural/ne_50m_admin_0_countries.zip (public domain but be nice and add attribution “Geometries from Natural Earth”)
4. Open QGIS, Layer -> Add Vector Layer -> choose ne_50m_admin_0_countries.shp
5. Unfortunately the csv is not simple, it has more than one row per country as it includes time series. And it does not have the value we want to map precalculated.
Afghanistan,AFG,"Literacy rate, adult female (% of females ages 15 and above)",SE.ADT.LITR.FE.ZS,,,,,,,,,,,,,,,,,,,,4.98746100000000E+00,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, Afghanistan,AFG,"Literacy rate, adult male (% of males ages 15 and above)",SE.ADT.LITR.MA.ZS,,,,,,,,,,,,,,,,,,,,3.03077500000000E+01,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, Afghanistan,AFG,"Literacy rate, adult total (% of people ages 15 and above)",SE.ADT.LITR.ZS,,,,,,,,,,,,,,,,,,,,1.81576800000000E+01,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, Afghanistan,AFG,"Literacy rate, youth female (% of females ages 15-24)",SE.ADT.1524.LT.FE.ZS,,,,,,,,,,,,,,,,,,,,1.11428000000000E+01,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, Afghanistan,AFG,"Literacy rate, youth male (% of males ages 15-24)",SE.ADT.1524.LT.MA.ZS,,,,,,,,,,,,,,,,,,,,4.57960200000000E+01,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, Afghanistan,AFG,"Literacy rate, youth total (% of people ages 15-24)",SE.ADT.1524.LT.ZS,,,,,,,,,,,,,,,,,,,,3.00663500000000E+01,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, |
This step is probably the hardest. I will use some Unix tools as I am used to them and they work well. Sorry! You can probably do this with a good texteditor or spreadsheet application as well.
We have “csvcut -c 2 WDI_Data.csv | uniq | wc -l” -> 253 -> 252 country codes (without the header). We have 6 lines per country for the literacy data. We should have at max 252 unique values per field then. TheZeitgeist only used data from 2011.
To make it more convenient to work, I first split off the Literacy data into a new file with
head -n 1 WDI_Data.csv > Literacy.csv; grep Literacy WDI_Data.csv >> Literacy.csv |
No idea if TheZeitgeist mixed Adult and Youth, let’s just use the Adult data for now.
head -n 1 WDI_Data.csv > Literacy_adult.csv; grep -E "Literacy rate, adult (fe)*male" Literacy.csv >> Literacy_adult.csv |
Next let’s isolate the data for 2011. csvcut seems to have a bug with numerically named columns so we have to use the field’s index (56) instead of its name “2011”.
csvcut -c 2,3,56 Literacy_adult.csv > Literacy_adult_2011.csv |
We need to get the data into one line per country, I am lazy so:
grep "Literacy rate, adult female" Literacy_adult_2011.csv > Literacy_adult_2011_female.csv grep "Literacy rate, adult male" Literacy_adult_2011.csv | sed 's/.*15 and above)",/,/' > Literacy_adult_2011_male.csv echo "Country Name,Country Code, Literacy Female, Literacy Male" > Literacy_adult_2011_oneline.csv; paste -d "" Literacy_adult_2011_female.csv Literacy_adult_2011_male.csv >> Literacy_adult_2011_oneline.csv |
Enough of that commandline mumbojumbo! QGIS time!
Natural Earth has a column named “wb_a3” which is the WB 3 letter country codes, yay!
toreal("Literacy_adult_2011_oneline_Literacy Female") - toreal("Literacy_adult_2011_oneline_Literacy Male")
Figure out the rest yourself. This is where I apparently lost interest in writing back then. ;)
—–
Now make the map better by choosing a projection that does not make Greenland as big as Africa. Also, I would try adding another “attribute” to the display, change the alpha value depending on the absolute literacy.
And finally realise that a map is not a good visualisation because you cannot see the values of tiny countries. Make a bar chart instead. ;)
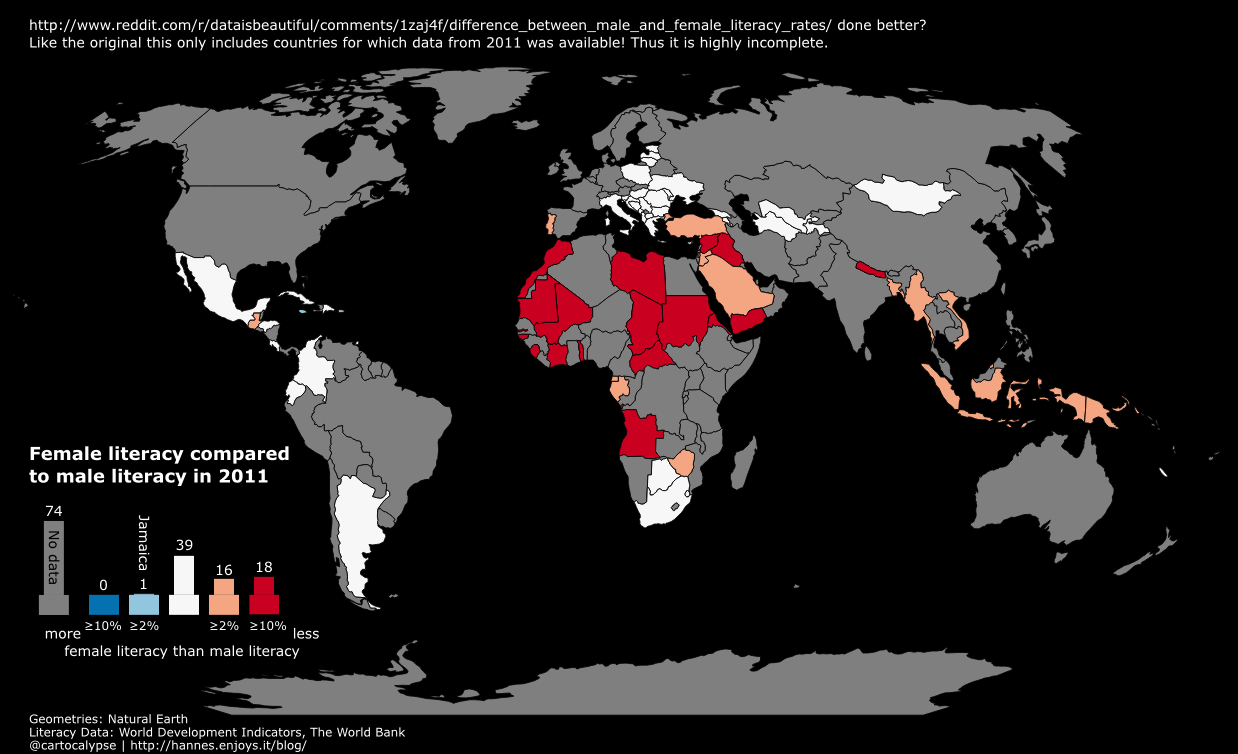
Ich hatte diese Kritik im Rahmen des (wahnsinnig tollen) Daten-Labors 2015 nebenbei geäußert und dann aufgrund des Interesses versprochen meine Gedanken aufzuschreiben. Hier sind sie nun endlich.
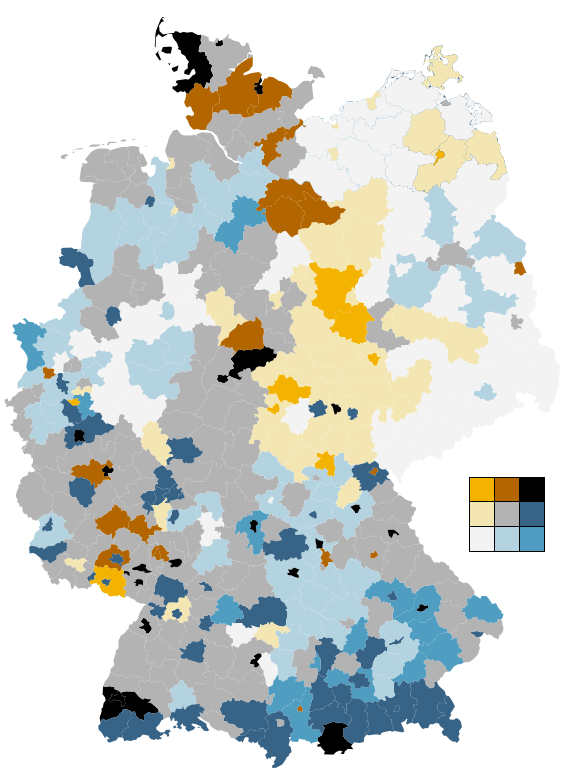
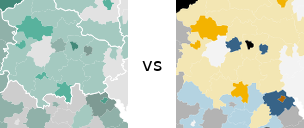
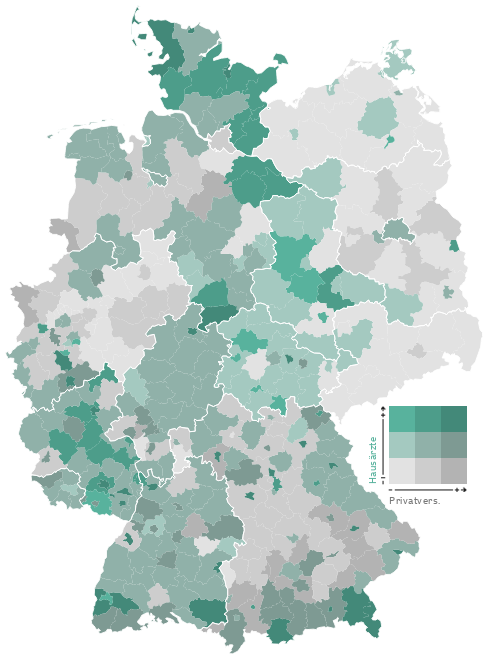
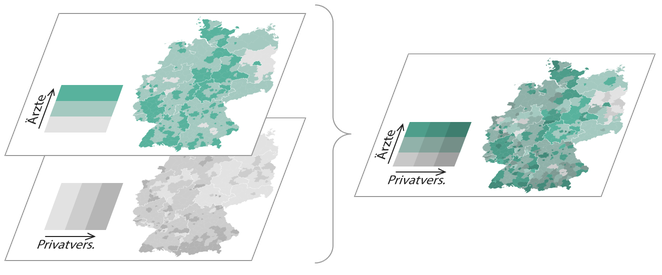
Geld zieht Ärzte an, so titelte die Zeit Online vor einigen Monaten über einer Recherche zum Verhältnis der räumlichen Verteilung von Ärzten im Vergleich mit verschiedenen demographischen Faktoren. Integraler Bestandteil des Artikels sind komplexe Karten und Diagramme. Die Redakteure versuchten sich an der Verwendung einer bivariaten Klassen-/Farb-Skala, doch leider ging die Wahl der Farben daneben, so dass das Endprodukt ineffektiv und irreführend ist. Es geht mir hier ausschließlich um die kartografische Darstellung. Zum Inhalt und der Datenanalyse kann ich nichts sagen!
So funktionieren die Karten: Grau steht für Privatpatienten, Grün für Ärzte. Zu den drei Helligkeitsstufen (je dunkler, desto höher der Anteil der Privatversicherten) kommt die Farbe dazu (je intensiver, desto mehr Ärzte pro Einwohner) So ergeben sich neun verschiedene Werte für die Einfärbung der Karten.
Quelle: http://www.zeit.de/feature/gesundheit-arzt-privat-versicherung-praxis
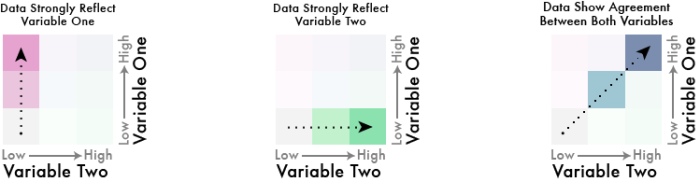
In einer bivariaten Skala wird das Verhältnis zweier Variablen zueinander/miteinander in vollem Detail dargestellt. Anstelle einer einzelnen Verhältniszahl sind hier mehrere Achsen im Gebrauch und damit die einzelnen Werte der Variablen nachvollziehbar. Solche Skalen sind in der Kartographie an sich nichts neues, werden allerdings (aufgrund der Komplexität meiner Meinung nach zu Recht) eher selten verwendet. Im Frühjahr 2015 veröffentlichte Joshua Stevens einen fantastischen Artikel, dessen Lektüre ich vor dem Weiterlesen sehr empfehle.
Joshua zeigt dort, wie aus den jeweiligen Farbskalen der beiden Attribute eine gemischte “Matrix” entsteht. Die Diagonale wird hierbei zu einem neuen sequenziellen Farbverlauf, der das neutrale Verhältnis der Variablen anzeigt. Die Farbskalen müssen dementsprechend mit Bedacht gewählt werden, so dass sich bei ihrer Vermischung eine sinnvolle, geordnete und “eigenständige” Skala entsteht.
Quelle: http://www.joshuastevens.net/cartography/make-a-bivariate-choropleth-map/
In Joshuas Beispiel sind (relativ) klar differenzierbar und identifizierbare Achsen entstanden, die dem Kartenbetrachter (mit etwas Anstrengung) ermöglichen, die Karte korrekt zu interpretieren. Man kann anhand der Farbe das jeweilige Verhältnis und die absoluten Werte lesen. Die Farbachsen sind intuitiv korrekt sortierbar.
Wie sieht es mit dem Farbschema der Zeit aus? Leider nicht gut.
Die Redakteure wählten für die eine Variable einen Farbverlauf von Grau nach Grün, für die andere einen von Grau nach Dunkelgrau (siehe oben). Die diagonale Farbskala entsteht also aus der Vermischung von Grün und Grau. Was passiert, wenn man Grün und Grau mischt? Man bekommt Farbtönen zwischen Grün und Grau… Die Farben auf der Diagonalen werden also sehr ähnlich zu zumindest einer der Hauptachsen. Damit zeigen sich Farben im Kartenbild, deren Ordnung der Betrachter unmöglich intuitiv und auch mithilfe der Legende kaum mental durchführen kann. Und genau das können wir hier sehen:
Als kleine Demonstration wieviele Details und Strukturen tatsächlich in den Daten stecken, habe ich einfach mal eine bivariate Farbskala von Cynthia Brewer auf die Daten geworfen. Achtung: Ich habe die Klassen nicht genau so legen können (Faulheit), wie sie in der Ursprungskarte vorliegen! Grundsätzlich dürfte die Aussage der Karte aber stimmen. Die Ästhetik steht erstmal an zweiter Stelle. ;)
The coordinates are wrong, I should have be xmin and ymin to match the official grid. Will update the PDFs soonish, sorry!
The LGV offers their official UTM grid for Hamburg in the Transparenzportal. Since many datasets are indexed by those grid tiles, it can be handy to have a quick references. Queue QGIS!
Load the layers “utm_raster1km any” and “utm_raster2km any” of the GML file. The CRS is EPSG:25832. Set their styles to have no fill.
Label with substr(x_min($geometry),0,4) || '\n' || substr(y_min($geometry),0,5) to truncate the coordinate display to just the interesting bits, the three leading numbers of X and the four leading numbers of Y.
Print them. You now have nice maps of the grid that you can use as reference when browsing through files with names like dgm1_32552_5936_2_fhh.xyz, LoD1_571_5939_1_HH.xml or dop20c_32576_5953.jpg (ignore the leading 32…).
I added the Stadtteile as background (and Wished QGIS could style by the 4 color theorem).
Click to download PDFs (they should be DIN A4, ask the composer why they are not):

Daniel P. Huffman shared this gorgeous map earlier. ArcMap just got the functionality to create such contour lines.

Naturally I had to try to re-create that style in QGIS. I semi-succeeded:
You have a DEM, eg mtsthelens_after.zip. Generate a hillshade from DEM. Generate contour lines from DEM.



Split the lines by segment, for example with the “Network” plugin. Select all features on your layer and then use its “Split” function.
Calculate the azimuth of each line. See this magical formula (I wish QGIS would have a function ready).
Rotate the angle according to your hillshade light angle. For example:
CASE
WHEN ("azimuth"+270) > 360
THEN ("azimuth"+270-360)/500
ELSE ("azimuth"+270)/500
END
And use that to scale your lines’ widths (the 500 is a constant factor here to get them small enough).
Disable all layers but hillshade and contour lines.
Move hillshade above contour lines.
Set map background to black (equals 0 in the blending multiplication later).
Use black to white as color ramp for the hillshade.
Set hillshade’s blending mode to multiply.
You now have the bright parts of the contour lines. Unfortunately QGIS does not yet support blending modes for whole groups so you will have to combine this with the next step in a raster graphics tool of your choice. Gimp works fine.
Take a screenshot of something.
Invert hillshade color ramp to white to black.
Rotate your angle by 180 (so it would be 90 instead of 270 in the example above).
You now have the dark lines.
Take another screenshot.


Add both images to a image in Gimp, Color to Alpha with black, invert the dark one, choose nice background, done!

This is still pretty rough as it’s mostly hack after hack and not “done properly”™. The blending adds some shadows where there should not be. In a way the lines end up being same width because of this. The scaling was done arbitrarily, there is probably some smart way with a better scale. Some fancy smoothing of the lines would look great. Coloring the areas between the lines would probably improve it as well. Once QGIS gets support for blending modes of groups, this will be much easier.
tl;dr: GMT is documented for people who use it since the 80s.
update 2: You can use gmtinfo to calculate the extents, using -I- will make it output the -R parameter! xyz2grd $(gmtinfo -I- *.xyz) ...
update: xyz2grd supports GeoTIFF via its GDAL driver (now?)! For example -Gfile.tif=gd:GTiff. See eg http://gmt.soest.hawaii.edu/doc/5.2.1/grdconvert.html. So the way below is overly complicated. I do not know how to apply the advanced settings of GDAL though like compression and prediction etc.


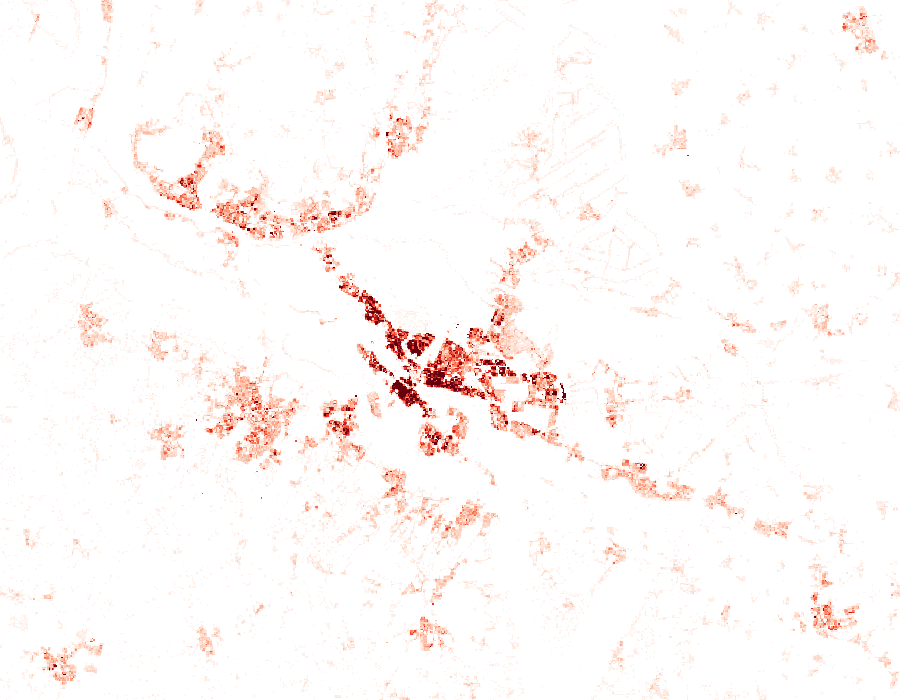
The Statistische Ämter des Bundes und der Länder offer a 100 meter grid of Germany’s population density: csv_Bevoelkerung_100m_Gitter.zip (110MB). Datensatzbeschreibung_Bevoelkerung_100m_Gitter.xlsx provides additional information.
Let’s turn that dataset into a GeoTIFF so we can use it in our GIS. We will use free and open-source tools from GMT and GDAL. GDAL loves to interpolate values but our data is discrete/regular. We do not want any kind of interpolation. So xyz2grd from GMT is the best choice for turning the xyz data into a “continuous” GIS format (tell me if not).
Inside the zip is a 1.3GB file Zensus_Bevoelkerung_100m-Gitter.csv with about 36 million lines.
Gitter_ID_100m;x_mp_100m;y_mp_100m;Einwohner
100mN26840E43341;4334150;2684050;-1
100mN26840E43342;4334250;2684050;-1
…
100mN27407E44044;4404450;2740750;3
100mN27407E44045;4404550;2740750;31
100mN27407E44046;4404650;2740750;13
100mN27407E44047;4404750;2740750;14
100mN27407E44048;4404850;2740750;10
Datensatzbeschreibung_Bevoelkerung_100m_Gitter.xlsx says the coordinates are in ETRS89-LAEA Europe – EPSG:3035.
First we need to find out the geographic extends of the data, you could use your favourite cli tools for that, I wrote a quick .vrt file and used ogrinfo on that:
$ cat Zensus_Bevoelkerung_100m-Gitter.csv.vrt
<OGRVRTDataSource> <OGRVRTLayer name="Zensus_Bevoelkerung_100m-Gitter"> <LayerSRS>EPSG:3035</LayerSRS> <SrcDataSource>Zensus_Bevoelkerung_100m-Gitter.csv</SrcDataSource> <GeometryType>wkbPoint</GeometryType> <GeometryField encoding="PointFromColumns" x="x_mp_100m" y="y_mp_100m" /> </OGRVRTLayer> </OGRVRTDataSource>
$ ogrinfo -al Zensus_Bevoelkerung_100m-Gitter.csv.vrt
INFO: Open of `Zensus_Bevoelkerung_100m-Gitter.csv.vrt’ using driver `VRT’ successful.
Layer name: Zensus_Bevoelkerung_100m-Gitter
Geometry: Point
Feature Count: 35785840
Extent: (4031350.000000, 2684050.000000) – (4672550.000000, 3551450.000000)
…
xyz2grd wants xyz, nothing else. The Gitter_ID_100m column is redundant in any case, you can calculate it yourself from the x and y fields if needed. So first let’s convert it to a “x y z” format with awk. The separator is ;
awk 'FS=";" {print $2" "$3" "$4}' Zensus_Bevoelkerung_100m-Gitter.csv > Zensus_Bevoelkerung_100m-Gitter.xyz
Now we can write our xyz2grd commandline.
We have our extends:
-R4031350/4672550/2684050/3551450
We know the spacing is 100 units (meters):
-I100
There is one header line:
-h1
And of course we know that we want a “classic” netcdf4 chunk size, whatever that means. We knew that right away, not after googling helplessly for an hour and eventually finding the hint on some mailing list. Not knowing this might have lead to QGIS only seeing NaN values for z, R’s ncdf/raster saying “Error in substr(w, 1, 3) : invalid multibyte string at ‘<89>HDF” and GDAL “0ERROR 1: nBlockYSize = 130, only 1 supported when reading bottom-up dataset”.
--IO_NC4_CHUNK_SIZE=c
The resulting commandline:
xyz2grd -Vl -R4031350/4672550/2684050/3551450 -I100 -h1 --IO_NC4_CHUNK_SIZE=c -GZensus_Bevoelkerung_100m-Gitter.cdf Zensus_Bevoelkerung_100m-Gitter.xyz
You can inspect the file with grdinfo and gdalinfo now if you want.
Let’s turn it into a GeoTIFF with gdal_translate. We will need a bunch of commandline parameters.
The spatial reference system is EPSG:3035, so:
-a_srs EPSG:3035
Values of -1 mean “no data”:
-a_nodata -1
TIFF is uncompressed by default, we want good lossless compression:
-co COMPRESS=DEFLATE
The resulting commandline:
gdal_translate -co COMPRESS=DEFLATE -a_srs EPSG:3035 -a_nodata -1 Zensus_Bevoelkerung_100m-Gitter.cdf Zensus_Bevoelkerung_100m-Gitter.tif
The resulting file is about 8 Megabytes and should work in any reasonable GIS. Have fun!
http://hannes.enjoys.it/opendata/Zensus_Bevoelkerung_100m-Gitter.tif
TODO: What license is this now?



Auf den großartigen Seiten des Hamburger Luftmessnetz kann man schöne Diagramme der verschiedenen Messwerte sehen, zum Beispiel von Feinstaub: PM10 oder PM2,5. Leider kann man nicht auf Diagramme sämtlicher Stationen verlinken, stattdessen muss der Benutzer sie per Hand zusammenstellen. Weil ich die Kurven gerne auf /r/dataisbeautiful verlinken wollte und die neuen Regeln dort etwas eigen sind, habe ich die Diagramme einfach mal mit Gnumeric nachgebaut.
Erstmal die Teilchen mit einem aerodynamischen Durchmesser von weniger als 10 Mikrometer (10 µm), PM10. Hiervon darf 35 mal Im Jahr ein Tagesmittelwert von 50µg/m³ überschritten werden.

Und dann noch die fieseren PM2,5 (kleiner 2,5µm), diese werden nur an drei Stationen gemessen:

In Berlin gibt es diese Werte leider nur täglich, aber der Feinstaub-Monitor der Berliner Morgenpost ist einen Blick wert (auch wenn er leider 2014 zu Ende gegangen ist?).
English version: This image shows the amount of particulate matter with a diameter of 10 micrometres or less in the days before and during new year 2014/2015 in Hamburg, Germany. This image shows the amount of particulate matter with a diameter of 2.5 micrometres or less.
Auch bundesweit gibt es schöne Werte, leider nur täglich. Das Umweltbundesamt stellt interpolierte Karten bereit, ich hab die letzten vier Tage mal zusammengefasst:

Schade, dass die Farbskala ein fixes Maximum hat, die Werte lagen ja wohl eher über 50µg/m³.
Wie auch immer, frohes neues!
 Weil ich immer wieder danach suche und sie dann per Hand mache… Als minlon,minlat,maxlon,maxlat: 9.65,53.38,10.33,53.75. Großzügig bemessen und ohne Garantie. Andere BBOXen finden sich bei http://osmtipps.lefty1963.de/
Weil ich immer wieder danach suche und sie dann per Hand mache… Als minlon,minlat,maxlon,maxlat: 9.65,53.38,10.33,53.75. Großzügig bemessen und ohne Garantie. Andere BBOXen finden sich bei http://osmtipps.lefty1963.de/

{kind=link}
{kind=link}