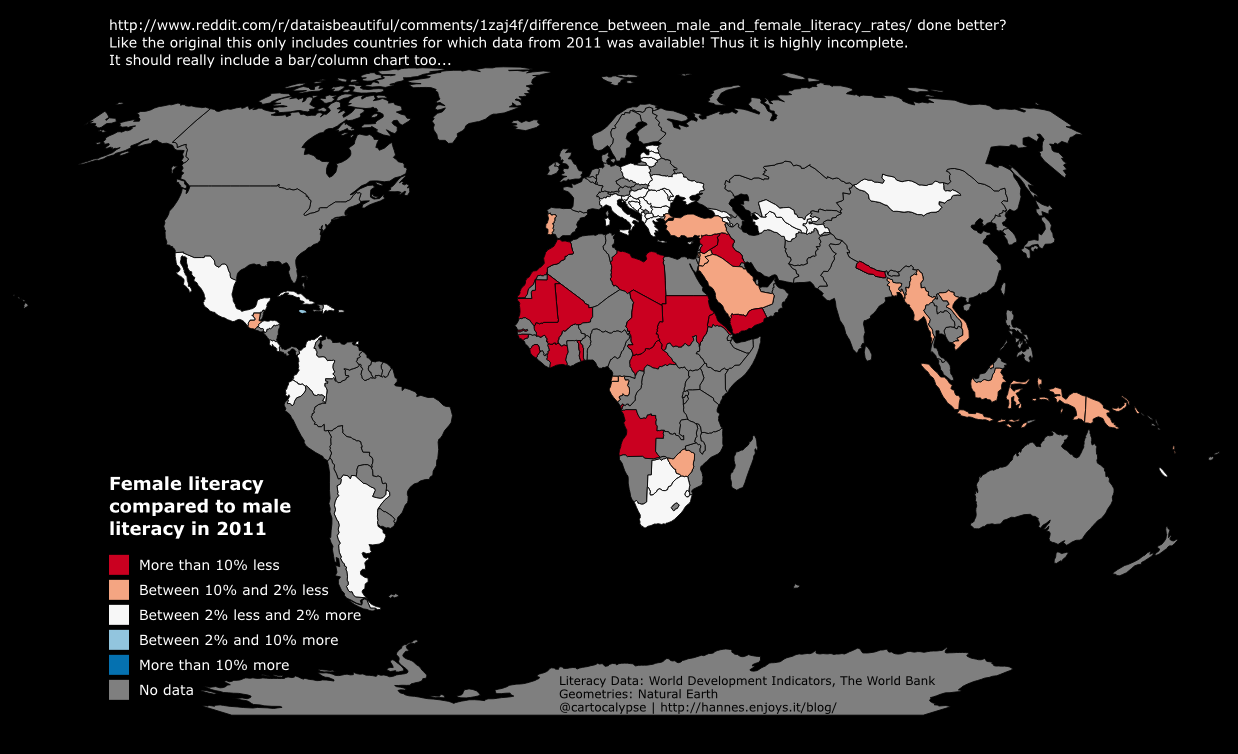
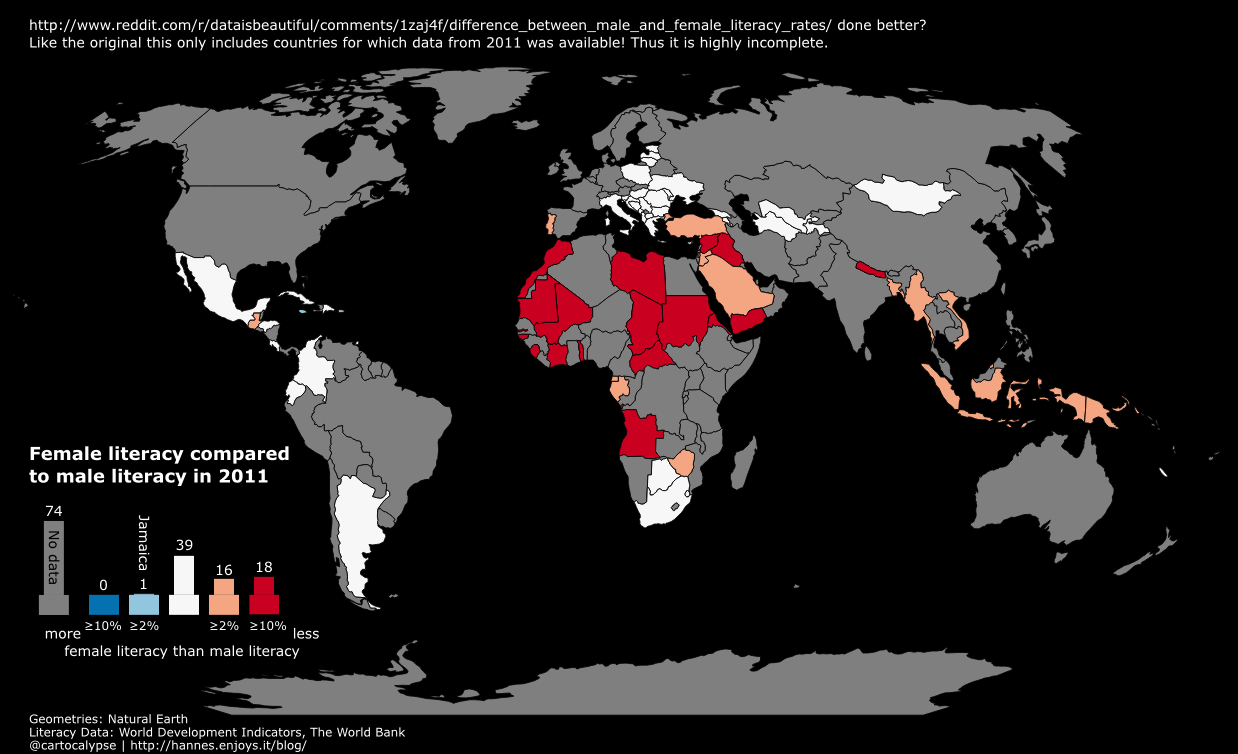
Let’s take it to the next level: Wir wollen alle auf daten-hamburg.de gehosteten Datensätze, weil da die ganzen schicken Geodaten sind. Wir müssen also einen Query bauen, der uns alle Datensätze gibt, die “^http://daten-hamburg.de/” in der resources.url haben.
Mit http://wiki.apache.org/solr/CommonQueryParameters kann man komplexe Queries schreiben, sagt http://docs.ckan.org/en/latest/api/index.html#ckan.logic.action.get.package_search . Mit ein bisschen Scrollen stößt man gegebenenfalls auf resource_search und über Google nach “ckan resource_search” auf https://github.com/ckan/ckan/issues/1494, dessen Query man dann nimmt und sich damit nach http://suche.transparenz.hamburg.de/api/action/resource_search?query=url:http://daten-hamburg.de/ durchhangelt. Voll einfach! … Der Query dauert mehrere Sekunden und scheint ALLE Hits zurückzugeben, super!
Download läuft, so langsam wie daten-hamburg.de eben leider ist: https://www.datenatlas.de/geodata/public/sources/
Insgesamt sind es rund 104 Gigabyte, allerdings inklusive einiger Duplikate. Übrigens stecken auch SHA256-Hashes in den Daten, praktisch zum Überprüfen der Downloads.
Ugly-but-does-the-job URLs rausziehen:
$ cat suche.transparenz.hamburg.de/api/action/resource_search@query\=url%3Ahttp%3A%2F%2Fdaten-hamburg.de%2F | json_pp | grep '"url"' | grep -Eo 'http.*"' | sed 's#"$##' > urls