Ach nee, der LGV hat ein bildbasiertes DOM von Hamburg im Transparenzportal veröffentlicht… Und sogar gleich zwei, eins von 2018, eins von 2020. Die Rasterweite ist 1 Meter, ob das wohl so vorlag oder für die Veröffentlichung gefiltert wurde?
Egal. Das ist ja großartig! Da werden eine Menge von Anwendungen ermöglicht (Sichtachsen! Verschattungen! Vermaschung! VR! AR!) und verschiedenste Akteure werden die Daten absolut feiern. Auch wenn es mit 1 Meter Auflösung wirklich mies grob ist, auf ein 1 Meter Gitter gerastert ist (nicht ausgedünnt, d. h. es ist teilweise stärker verfälscht und “daneben”) und “nur” bildbasiert (nicht gescannt) ist, geht da schon einiges mit.








Ausprobieren! Im Browser!
Achtung, frickelige Bedienung! Am besten den WASD-Möwen-Modus nutzen, mit Speed 1000. Oder mit einem Doppelklick irgendwo hinzoomen.
https://hamburg.datenatlas.de/DOM1_XYZ_HH_2018_04_30-colored.html
https://hamburg.datenatlas.de/DOM1_XYZ_HH_2020_04_30-colored.html
Datenaufbereitung als LAZ
Für 2018 liegen die Daten als 12768 einzelne XYZ-Kacheln vor, also als super ineffiziente Textdateien. Insgesamt sind es rund 22 Gigabyte. Für 2020 sind es stattdessen 827 größere Kacheln, aber ebenfalls in XYZ mit einem ähnlichem Platzbedarf.
Schönerweise gibt es freie Tools wie LAStools‘ txt2las, was sie schnell und einfach ins super effiziente LAZ-Format umwandeln kann:
txt2las -i DOM1_XYZ_HH_2018_04_30/*.xyz -epsg 25832 -odir /tmp/laz/ -olazHat bei mir ungefähr 5 Minuten gebraucht und da waren es nur noch 700 Megabyte. Das ZIP war übrigens mehr als 3 Gigabyte groß.
Zusammengefasst werden können die einzelnen Dateien mit lasmerge:
lasmerge -i /tmp/laz/*.laz -olaz -o DOM1_XYZ_HH_2018_04_30.lazInteraktive 3D-Webanwendung
Dann noch schnell in den großartigen PotreeConverter von Markus Schütz geschmissen mit
PotreeConverter DOM1_XYZ_HH_2018_04_30.laz -o web/ --encoding BROTLI \
--generate-page DOM1_XYZ_HH_2018_04_30 --title DOM1_XYZ_HH_2018_04_30und 4 Minuten später ist die interaktive 3D-Webanwendung fertig, wegen der zusätzlichen Octree-Struktur jetzt bei rund 3 Gigabyte.
Punktwolke mit Farben aus Orthophoto einfärben
Die bereitgestellten Oberflächenmodelle sind so schlicht wie es nur geht, es sind reine XYZ-Daten ohne weitere Dimensionen wie Farbe o. ä.
Glücklicherweise gibt es ja auch die Orthophotos, eventuell wurde sogar dasselbe Bildmaterial genutzt? Da müsste mal jemand durch den Datenwust wühlen, die bei den DOPs werden die relevanten Metadaten nicht mitgeliefert…
Theoretisch könnte man sie also einfärben. Leider ist lascolor proprietär und kommt mit gruseligen, bösartigen Optionen, wenn man es wagt es “unlizenziert” zu nutzen (“Please note that the unlicensed version will (…) slightly change the LAS point order, and randomly add a tiny bit of white noise to the points coordinates once you exceed a certain number of points in the input file.”) und kann JPEG in GeoTIFF nicht lesen (so hab ich mir die DOPs aufbereitet). Eine Alternative ist das geniale PDAL. Mit einer Pipeline wie
{
"pipeline": [
"DOM1_XYZ_HH_2020_04_30.laz",
{
"type": "filters.colorization",
"raster": "DOP20_HH_fruehjahrsbefliegung_2020.tif"
},
{
"type": "filters.assign",
"value" : [
"Red = Red * 256",
"Green = Green * 256",
"Blue = Blue * 256"
]
},
{
"type": "writers.las",
"compression": "true",
"minor_version": "4",
"filename":"DOM1_XYZ_HH_2020_04_30-colored.laz"
}
]
}und
pdal pipeline DOM1_XYZ_HH_2020_04_30.laz+DOP20_HH_fruehjahrsbefliegung_2020_90.cog.tif.jsonist die Punktwolke innerhalb von Minuten coloriert und kann dann wie gehabt mit PotreeConverter in einen interaktiven 3D-Viewer gesteckt werden.
Update 2023: "minor_version": "2" -> "minor_version": "4", damit LAS 1.4 rauskommt, um dann einfach COPC draus bauen zu können (Farben als 16-Bit, nicht 8-Bit). Und entsprechend noch ein Filter, um die Farben auf den 16-Bit-Wertebereich zu skalieren, das passiert leider nicht automatisch.
Das Ergebnis ist besser als erwartet, da es scheinbar tatsächlich die selben Bilddaten sind (für beide Jahre). Andererseits ist es auch nicht wirklich schick, da die DOPs nicht als True Orthophoto vorliegen und damit höhere Gebäude gekippt in den Bilder abgebildet sind. Sieht man hier schön am Planetarium.




Cloud-Optimized Point Cloud
Als Cloud-Optimized Point Cloud umwandeln kann man das Resultat einfach mit untwine (mit pdal pipeline braucht man immens viel RAM (>64GB), da die Umwandlung nach COPC hier nicht den Streaming Mode nutzen kann):
untwine -i DOM1_XYZ_HH_2020_04_30-colored.laz -o DOM1_XYZ_HH_2020_04_30-colored.copc.laz --single_file
Anschließend auf einem Server (mit entsprechenden Access-Control-Allow-Headern) gelagert, kann die Punktwolke super einfach mit https://viewer.copc.io/?resources=https://example.com/pointcloud.copc.laz im Browser verwendet werden. Ganz ohne Umwandlung in viele Unterdateien wie beim PotreeConverter.
DOM als GeoTIFF
Wer es lieber als GeoTIFF haben möchte, hat es etwas schwerer, denn GDAL kommt mit dieser Art von Kacheln (mit Lücken und in der bereitgestellten Sortierung) nicht gut klar. Mein Goto-Tool dafür ist GMT.
gmt xyz2grd $(gmt gmtinfo -I- *.xyz) -Vl -I1 -G/tmp/gmt.tif=gd:GTiff *.xyzDas so erstellte GeoTIFF kann anschließend mit GDAL optimiert werden (ab GDAL 3.2.3/3.3):
gdal_translate -of COG -co COMPRESS=DEFLATE -co PREDICTOR=2 \
--config GDAL_NUM_THREADS ALL_CPUS --config GDAL_CACHEMAX 50% \
-a_srs EPSG:25832 /tmp/gmt.tif DOM1_XYZ_HH_2020_04_30.tifHier mal im Vergleich mit dem DGM1 als Schummerungen:
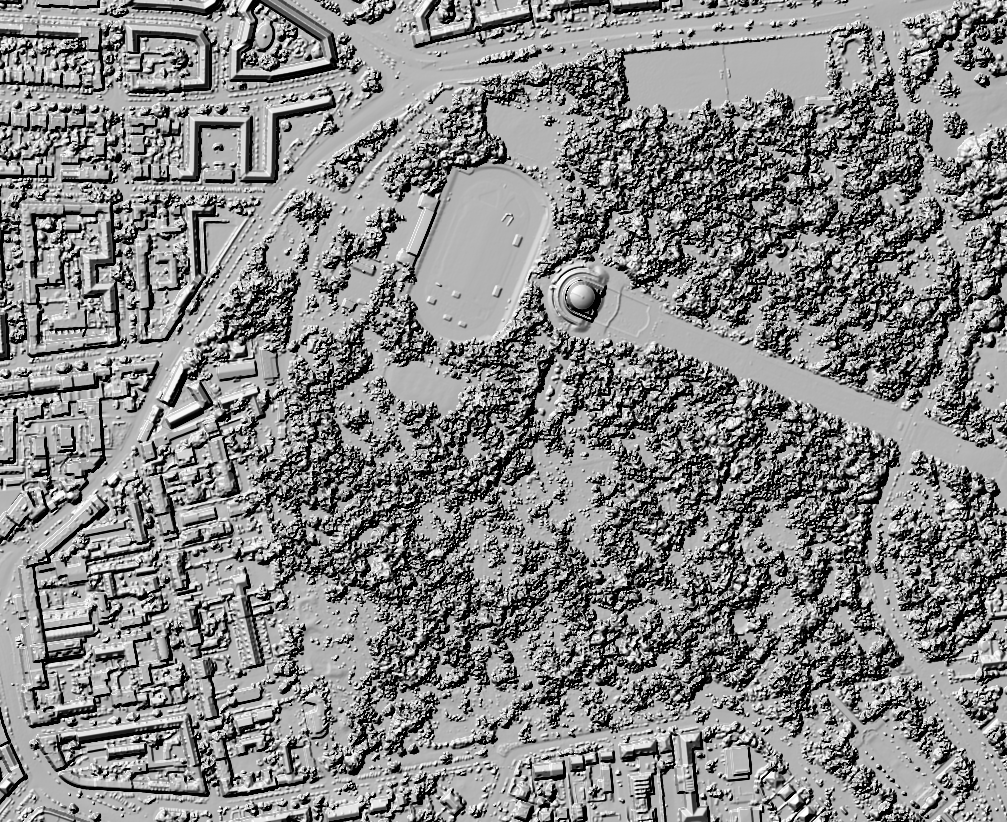





Vermaschung als 3D-Modell
Leider habe ich keine gute Lösung für die 3D-Vermaschung gefunden. tin-terrain und dem2mesh kommen nicht mit so großen Datenmengen auf einmal klar und weiter hab ich nicht geschaut. Wer da was gutes weiß kann sich bei mir bei nächster Gelegenheit Kekse oder Bier abholen. ;)
Daten hinter den Bildern und den Viewern
Datenlizenz Deutschland Namensnennung 2.0, Freie und Hansestadt Hamburg, Landesbetrieb Geoinformation und Vermessung (LGV)











{kind=link}